There is something you need to know about me.\n\nI’m a huge fan of continuous integration.\n\nIf you put me on a new software development team and you don’t already have an automated build process and continuous integration set up, you can pretty much bet that the first thing I am going to do is get all of that going.\n\nI love the idea of automation.\n\nI love making things more efficient and automatic, whenever possible.\n\nTo me, that is what continuous integration represents.\n\nIt’s taking that slow, painful, tedious, and error prone process of building the software, running tests against it, getting it packaged up to be deployed, and making it automatic.\n\nBut it’s much more than that.\n\nContinuous integration, or CI as it’s usually called, is also about increasing the frequency in which code that individual developers are working on is merged together, so you don’t end up in the kind of merge hell I mentioned in the chapters on source control quite as often.\n\nThe sooner you are able to integrate, the less chance for integration hell and the faster you will find integration issues.\n\nAnd finally, continuous integration provides the whole team with feedback—and fast.\n\nWhen you are able to check in some code and know in two minutes whether that code compiles and whether you broke something in five—all while seeing the results in one central location—you’ve got a very fast and useful feedback cycle.\n\nThe faster the feedback cycle, the faster software can evolve, and the more the overall quality can be improved—an extremely important element in Agile development.\n\nAt this point, you may be thinking, “Yeah, John, it really sounds like you are trying to sell me this thing called CI, but what exactly is it?\n\nI mean, it sounds good and all.\n\nI like automation. I like feedback. I don’t think I’d like integration hell.\n\n“But what exactly is this CI you speak of?”\n\nWell, I think the best way for you to understand continuous integration is for me to take you back in time to show you how things used to be done and how continuous integration evolved over time. Then, I’ll finally take you through the workflow of a modern software development environment with a good CI system up and running.\n\nLet’s begin the journey, shall we?\n\n
How Building Code Used to Work
\n\n \n\nI’m not super old, but I’m old enough to have built software in a time before there were fancy tools for automating it.\n\nEarly in my career—we are talking like early 2000s—it was pretty normal to work on a software development team where every single developer was responsible for figuring out how to create their own build of the software.\n\nWhat do I mean by this?\n\nWell, in any sufficiently large application, there are going to be quite a few components that may go into the build of the software being worked on.\n\nThere are of course going to be a large amount of source code files which must be compiled.\n\nOften, there will be some other resources like external libraries which will need to exist on a developer’s machine to build the final software solution.\n\nAnd there may be additional steps involved before or after the code is compiled to get the finished product.\n\nIt used to be that when you worked as a developer, you’d get a copy of the source code. Some guru who had been working on the software for the last five years would show you the magical incantations you needed to do to build the software, and then you were on your own.\n\nIndividual developers developed their own ways of getting the software build on their machines.\n\nWhen it was time to produce a build that was ready to be tested or deployed out to customers, one of the developers would sacrifice chickens, walk backwards in a circle, light candles around a pentagram, hit CTRL+SHIFT+F5, and out would pop a finished version of the software.\n\nThere were a few big problems with this way of developing and building software, though.\n\nThe biggest one was that since each developer was building the software on their own machines—and in slightly different ways—there was a huge chance that two developers with identical versions of the code could produce two completely different versions of the software.\n\nHow could this be, you might ask?\n\nPlenty of things can go wrong when you don’t have consistency, and everyone is following their own process of doing something.\n\nDevelopers could have different versions of external libraries installed on their machines.\n\nDevelopers could think they have the same source code, but actually forget to get the latest files from source control or had a local change made to a file, which they didn’t realize and that prevented the code from being updated.\n\nThe file or folder structure could be different, and that in turn could cause differences in how the software actually runs.\n\nPlenty of things could go wrong.\n\nThe other major problem was that since developers were all building locally, if someone checked in some code that didn’t even compile, no one would find out until they pulled down that code and tried to build the software.\n\nThis might not seem like a huge deal, but it gets really fun when multiple developers check in bad code over a period of days or even weeks, and then when someone finally tries to build everything and finds out it’s broken, they have no idea what change or changes caused the issues.\n\nPlus, I’ve worked at places where it literally took hours to just create a single build of the software.\n\nNothing worse than running a build on your machine for 4-5 hours and then finding out it’s broken.\n\n
\n\nI’m not super old, but I’m old enough to have built software in a time before there were fancy tools for automating it.\n\nEarly in my career—we are talking like early 2000s—it was pretty normal to work on a software development team where every single developer was responsible for figuring out how to create their own build of the software.\n\nWhat do I mean by this?\n\nWell, in any sufficiently large application, there are going to be quite a few components that may go into the build of the software being worked on.\n\nThere are of course going to be a large amount of source code files which must be compiled.\n\nOften, there will be some other resources like external libraries which will need to exist on a developer’s machine to build the final software solution.\n\nAnd there may be additional steps involved before or after the code is compiled to get the finished product.\n\nIt used to be that when you worked as a developer, you’d get a copy of the source code. Some guru who had been working on the software for the last five years would show you the magical incantations you needed to do to build the software, and then you were on your own.\n\nIndividual developers developed their own ways of getting the software build on their machines.\n\nWhen it was time to produce a build that was ready to be tested or deployed out to customers, one of the developers would sacrifice chickens, walk backwards in a circle, light candles around a pentagram, hit CTRL+SHIFT+F5, and out would pop a finished version of the software.\n\nThere were a few big problems with this way of developing and building software, though.\n\nThe biggest one was that since each developer was building the software on their own machines—and in slightly different ways—there was a huge chance that two developers with identical versions of the code could produce two completely different versions of the software.\n\nHow could this be, you might ask?\n\nPlenty of things can go wrong when you don’t have consistency, and everyone is following their own process of doing something.\n\nDevelopers could have different versions of external libraries installed on their machines.\n\nDevelopers could think they have the same source code, but actually forget to get the latest files from source control or had a local change made to a file, which they didn’t realize and that prevented the code from being updated.\n\nThe file or folder structure could be different, and that in turn could cause differences in how the software actually runs.\n\nPlenty of things could go wrong.\n\nThe other major problem was that since developers were all building locally, if someone checked in some code that didn’t even compile, no one would find out until they pulled down that code and tried to build the software.\n\nThis might not seem like a huge deal, but it gets really fun when multiple developers check in bad code over a period of days or even weeks, and then when someone finally tries to build everything and finds out it’s broken, they have no idea what change or changes caused the issues.\n\nPlus, I’ve worked at places where it literally took hours to just create a single build of the software.\n\nNothing worse than running a build on your machine for 4-5 hours and then finding out it’s broken.\n\n
Then Build Servers Came Along
\n\nOne of the early ways to solve these kinds of problems was the introduction of builder servers.\n\nThe idea was that instead of having every developer build the software on their own machine, there would be one central build server, which was configured correctly and had all the right versions of the libraries, etc.\n\nA developer could kick off a build on the build server, or the build server would automatically build the software every night.\n\nAt first, this started out as weekly builds.\n\nSo, you’d at least have some official weekly build of the software that combined all the changes from all the developers from that week together and was built in a uniform way.\n\nOne issue with the weekly build, though, was that often—especially with large teams—there would be an integration hell problem when trying to get that weekly build created.\n\nOften, there would be a developer or IT person in charge of getting that weekly build to work, and they’d manually fix all the issues that were breaking the build and hunt down developers with conflicting changes to try and resolve them.\n\nAn improvement over no build server, but not by much.\n\nEventually, the idea of nightly builds became popular.\n\nThe idea was that if we integrated the code daily with the build server creating a new build every night, there would be less time for big issues to pile up and compound, and we could catch problems much earlier.\n\nAt first, this idea seemed crazy.\n\nYou wouldn’t believe the amount of resistance I got the first time I ever suggested a nightly build at one of the companies I worked for.\n\nBut, eventually it became the norm, and it did solve quite a few problems.\n\nNightly builds from a central build server helped get everyone synced up and on the same page, so to speak, and if the nightly build broke, it was everyone’s top priority to get it working again.\n\nThe idea of a nightly build pushed forward the need for actual automation of the build process itself.\n\nThis was very good.\n\nIn order to consistently build the software each night, we needed some automated way to get all the code together, compile it, and do any of the other steps required to create a working build.\n\nThis was the era of many scripts which were created in order to automate the process of building the software, at least on the build machine. It was still quite normal for developers to still have their own local build processes.\n\nMakefile scripts, which used to only compile the code, started to become more sophisticated to handle the full build process for a build server, and XML-based build automation tools like Ant were created and became popular.\n\nLife was getting good, but there were still major problems.\n\nAs Agile was becoming more and more popular, and the idea of unit testing was gaining support, nightly builds that just compiled the code and packaged it up were not quite good enough.\n\nWe needed shorter feedback cycles.\n\nThe whole team could get derailed if someone checked in bad code, and we didn’t find out about it until the next morning.\n\nWe needed some way to build the code, reliably, multiple times per day and to run some other code quality checks besides just “it compiles.”\n\n
Finally, Continuous Integration
\n\n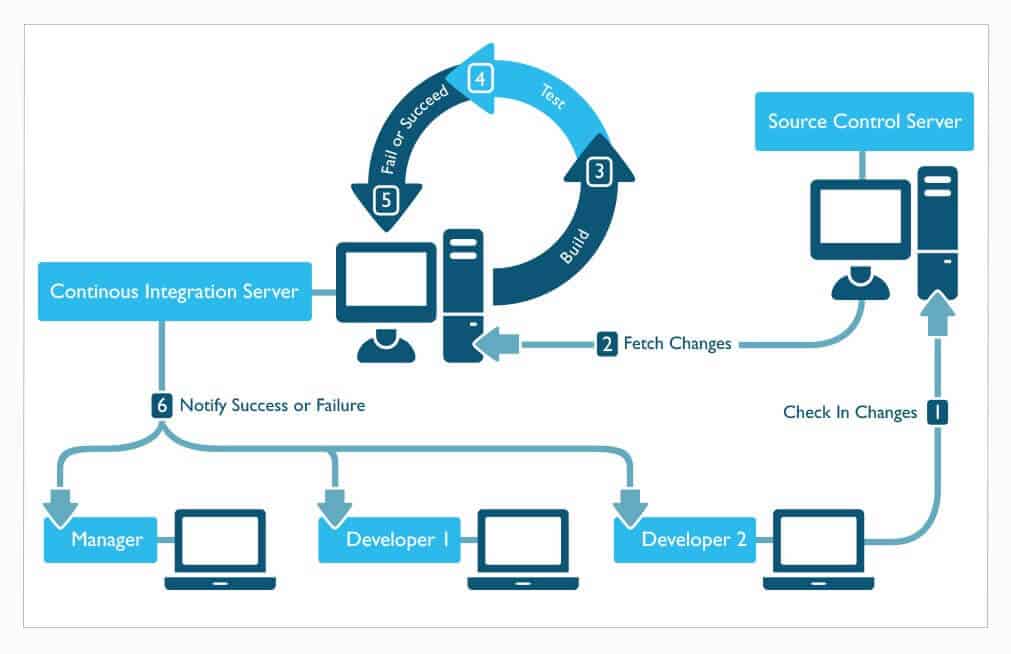
A Sample Continuous Integration Workflow
\n\nOk, so at this point, you probably have a decent idea of what continuous integration is by hearing about the problems it solved and how it evolved.\n\nBut you still might not quite “get it”—and that’s ok.\n\nLet’s walk through a sample workflow using continuous integration, and then maybe it will click a little better.\n\n
Check in code
\n\nThe cycle starts with you checking in your code.\n\nOf course, you’ve run the build on your local machine and run all the unit tests before you dare check in code to the main repository and risk breaking the build for everyone… right?\n\n
New build is kicked off
\n\nThe CI software sitting on the build server just detected a change to the source control branch it’s monitoring.\n\nIt’s your code! Oh goody!\n\nThe CI server kicks off a new build job.\n\n
Code is checked out
\n\nThe first thing the new build job does is to get the latest changes.\n\nIt pulls down your code changes—and any other ones on the branch—and puts them into its working directory.\n\n
Code is compiled
\n\nAt this point, a build script of some sort is usually kicked off to actually compile and build the code.\n\nThe build script will run the commands to build the source code.\n\nIt will also link in any external libraries or anything else needed to compile the code.\n\nIf the code fails to compile, the build will stop right here, and an error will be reported.\n\nThis is called breaking the build—and it’s bad.\n\nI thought you said you compiled the code on your machine before checking it in?\n\nShame!\n\n
Static analyzers are run
\n\n \n\nAssuming the code built correctly, static analyzers are run to measure certain code quality metrics.\n\nIf you don’t know what these are, that’s ok.\n\nBasically, they are tools that can take a look at the code and look for possible errors or violations of best practices.\n\nThe results from these analyzers are stored to be reported when the build is finished.\n\nSome builds can actually be set to fail if some threshold is not met for a code quality metric derived from the static analyzer.\n\n
\n\nAssuming the code built correctly, static analyzers are run to measure certain code quality metrics.\n\nIf you don’t know what these are, that’s ok.\n\nBasically, they are tools that can take a look at the code and look for possible errors or violations of best practices.\n\nThe results from these analyzers are stored to be reported when the build is finished.\n\nSome builds can actually be set to fail if some threshold is not met for a code quality metric derived from the static analyzer.\n\n
Unit tests are run
\n\nAssuming everything is still good, the CI job kicks off the unit tests.\n\nThe unit tests are run against the compiled code, and the results are recorded for later.\n\nUsually if any unit tests fail, this causes the whole build to fail. I highly recommend this approach.\n\n
Results are reported
\n\nFinally, the results of the actual build are reported.\n\nThe report will contain data about whether the build passed or failed, how long it took to run, code quality metrics, unit tests run, and any other relevant data.\n\nDocumentation might also be auto-generated by the build at this point as well.\n\nThe results can be set up to be emailed out to the team—especially in the case of a failure—and most CI software programs have a web interface as well where anyone can see the results of the latest build.\n\n
Software is packaged
\n\nNow the build software is packaged up into a form where it can be deployed or installed.\n\nThis usually involves taking the compiled code and any external resources or dependencies and packaging it up into whatever structure is necessary to have a deployable or installable unit.\n\nFor example, a file structure might be created that contains all the right files, and then the whole thing might be zipped up.\n\nAt this point, the build job may also apply some kind of tagging in source control to mark the version of the software.\n\n
Code is optionally deployed (continuous deployment)
\n\nThis last step is optional—actually, I suppose that the previous step is optional as well.\n\nBut more teams are doing continuous deployment where they deploy the code directly into an environment for it to be tested—or, if they are really brave, right into production.\n\n
Finished
\n\nAnd that’s it.\n\nThere are some variations in these steps, of course, and there may be some additional steps, but the basic idea is to build the code, check for problems, and get the code ready for deployment all automatically whenever new code is checked in.\n\nThis allows us to be able to know very quickly if a new change to the system caused an error, so that it can be fixed right away.\n\nEven though I’ve breezed over all of this, I don’t want to make it sound too simple.\n\nBuild engineers can spend quite a bit of time constructing a well-oiled continuous integration process, and there are all kinds of debates about how it should be done and what are the best practices for doing it.\n\n
CI Servers and Software
\n\n \n\nOne critical component of continuous integration is CI software.\n\nWithout CI software, we’d have to write custom scripts and essentially program our own build servers.\n\nFortunately, many smart developers quickly realized the value of building CI software, which helps to automate most of the common tasks of continuous integration.\n\nMost CI software works in a very similar manner, making it easy—or at least easier—to implement a workflow like the one I described above.\n\nThere are actually quite a few CI servers and software available, but I’m only going to highlight a few here that I have found to be the most commonly used at the time of writing this book.\n\n
\n\nOne critical component of continuous integration is CI software.\n\nWithout CI software, we’d have to write custom scripts and essentially program our own build servers.\n\nFortunately, many smart developers quickly realized the value of building CI software, which helps to automate most of the common tasks of continuous integration.\n\nMost CI software works in a very similar manner, making it easy—or at least easier—to implement a workflow like the one I described above.\n\nThere are actually quite a few CI servers and software available, but I’m only going to highlight a few here that I have found to be the most commonly used at the time of writing this book.\n\n
Jenkins
\n\nJenkins is pretty much my “go to” CI software.\n\nIt’s a Java program which was initially created to do CI in Java environments, but it’s become so popular and is so easy to use that it has expanded to become usable for just about any technology.\n\nJenkins is extremely easy to install and get running as it contains its own built-in webserver.\n\nIt also has a ton of plugins.\n\nIf you are trying to do something in Jenkins, there is a good chance someone has written a plugin to do it for you. That is one of the main reasons why I like and use Jenkins so much.\n\n(I actually have a Pluralsight course that talks you through the Jenkins basics.)\n\n
Hudson
\n\nI’m going to spare you the drama of the big long ass story about the Hudson / Jenkins split and give you the short of it.\n\nBefore Jenkins came along, there was Hudson.\n\nThere were some fights, Jenkins split off from Hudson, and Hudson continued to be developed on its own.\n\nHudson is controlled by Oracle, and I personally don’t think it’s as good as Jenkins, since the creator of Hudson, Kohsuke Kawaguchi, and most of the original Hudson team, moved to Jenkins.\n\nHonestly, I don’t know if Hudson is still alive and being worked on.\n\n
Travis CI
\n\nTravis is another popular CI software, but it operates a little bit differently.\n\nTravis CI is actually hosted and is provided as a service.\n\nIn other words, you don’t install Travis CI; you sign up for it.\n\nIt’s really designed to perform CI for projects hosted on GitHub.\n\nTravis is gaining popularity since many projects are hosted in GitHub, and it’s well-designed and easy to use.\n\nPlus, it’s nice to not have to maintain your own build server.\n\n
TFS
\n\nIf you are working exclusively in a Microsoft shop, TFS (Team Foundation Server) does offer continuous integration support, but in my experience, it’s pretty simplified and isn’t robust enough to compete with some of the other, more popular offerings.\n\nBut, I suppose if you want something simple—and it has to be a Microsoft solution—this one could work for you.\n\n
TeamCity
\n\nTeamCity is another popular continuous integration server, which is created by the commercial company JetBrains.\n\nIt has a free version, but it is also a licensed product.\n\nSo, if you are looking for something with a little more professional support, this is a good option.\n\nMany .NET teams use TeamCity for their CI needs.\n\n
More?
\n\nI’ve only given you a small sampling of some of the more popular options for CI servers, but there are quite a few in existence.\n\nCheck out this near complete and updated list if you want to see all the options.\n\n
\n\n

Related Articles

12 REALITIES of Daily Life as a Programmer
What’s the daily life of a programmer like? A programmer’s daily life consists of auditing and debugging code, coding new…

13 POWERFUL Productivity Tips for Developers
Great productivity is one of the best soft skills you can have as a developer. I’ve used these tips to…

Impostor Syndrome as a Programmer
Believing that you’re somewhat unqualified for your job is a problem faced by the best of us. When those thoughts…