As an Amazon Associate I earn from qualifying purchases.
A former fellow computer science student who is now a professor asked me to give a talk about DevOps. It seems to always be interesting for current students to hear some insights from people in the industry.
So, I prepared a talk and thought, why not make a blog post out of this? And here is the result.
If you prefer to watch the talk I gave that inspired this post, you can check it out here:
You will learn what DevOps actually means and how you can implement its practices in your daily working routine. Doing so will save your code from the apocalypse, which means not using any of this can cause you to lose your code, get lots of stress at work, and in the worst case, even lose your job. Shall we?
What Is DevOps?
There is no perfect definition for DevOps, but the following quote fits pretty well. DevOps is:
a set of practices that combines software development (Dev) and information-technology operations (Ops) which is intended to reduce the time between committing a change to a system and the change being placed into normal production, while ensuring high quality.
So, we have the development of software on one side and operating or running it on the other. The important factor is that lots of these practices can be automated, hence shortening the software development lifecycle.
Emotions or Motivation?
Before we get into the details of the DevOps practices and how they will benefit you, let’s talk about how DevOps might make you feel—and maybe how it will motivate you.
If you’re not implementing these practices at all, you might get into trouble. There are lots of tools that come with DevOps that will help you a lot when building your application. But if you’re not using any of these tools and practices, then—and believe me, I’ve been there—you might end up looking like this:

No DevOps at all. And ain’t that funny.
But when you do get started with the tools and concepts, the life of a developer gets easier!

You see, you might be more relaxed. Working on a project is fun. Maybe you can also grab a cup of coffee and just chill a little.
This is the most realistic scenario, or at least the most realistic goal.
Of course there’s also the dream where DevOps does everything for us. Everything is automated, you don’t have to do much anymore, and you can just chill on the beach.

But this is a utopia. We are not there yet. Our goal—your goal—should be the second picture.
Theory of DevOps
The theory of every software development life cycle is this: You want to turn coffee into profit.

The interesting part is the area in between. How do you get from coffee to profit?
Currently, that’s magic.

But guess what: It’s the kind of magic you can actually learn—and you don’t even need a magic wand. Keep reading, and by the end of this post, you’ll know how this magic works.
DevOps Magic and Its Benefits
Alright, now what is this DevOps magic?
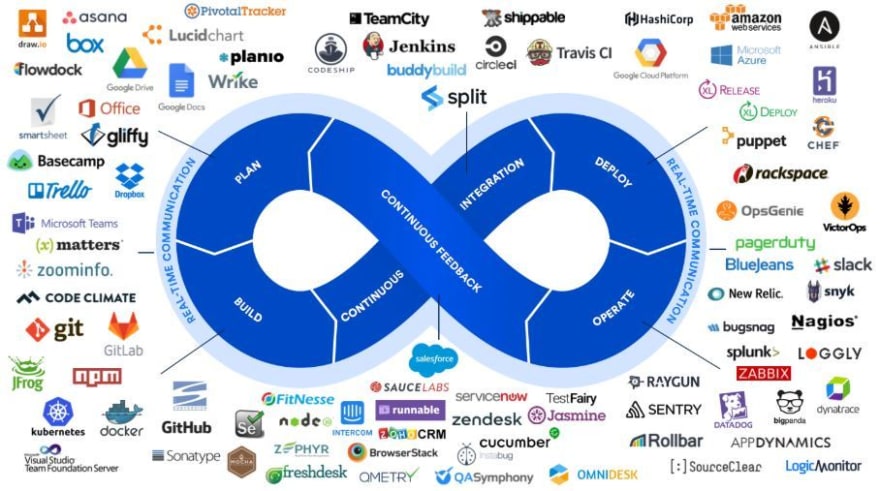
As you can see here, the process of developing software is not a clean line that moves you from point A to point Z. It’s a recurring process of six stages.
We start on the top left, with planning. You get your tasks and feature requests, and you might have an idea for what your project is all about. Then you should start planning this project. Again, it’s not planning the whole way from start to finish; you iterate through several steps during the development. There are great tools and concepts for that.
Next is the build phase. Now we’re talking about coding. You start your integrated development environment (IDE) and implement the features you planned in the phase before. In this step there are tools to make sure your code is safe, and you can go back if anything goes terribly wrong.
Continuous Integration is a great way to deploy your code automatically. Continuous integration and deploy somewhat go together. We will get to the details later. Just remember, it’s a great way to deploy the code of your whole team.
Apart from that, there are a few great platforms to deploy your code to. If you want to make a web application and use a service where this app is running, pay attention during the deployment part.
Now when your application is running, you might want to monitor it. Is the server always running? Do any errors occur? This is the operate phase. You can use available tools to do that or simply implement a small solution by yourself.
Finally you need feedback. Is your app doing what it’s supposed to do? Is it fun using it? All that can also be done, of course, with tools like bug trackers, and then you use the feedback to go back to the planning step.
All these steps are surrounded by communication. By far the most important part. You have to communicate with your team. The great thing is that you don’t have to leave your home to do that.
In the picture above you can see that there are lots of tools you can use in your software development life cycle. Don’t worry, there is no need to know every single one. I will give some hints as to which tool might be a good choice, though.
You might have heard of git and GitHub, Google Drive, Slack, and so on. Lots of options for you.
One more thing before we get into the details. Why should you bother? Why use even more tools? What are the benefits?
Benefits
Well, it starts with your code. It’s a lot easier to work together with your team using certain tools. The code quality of your team will improve.
You will need less time to develop. Deployment, in particular, can be a pain. You’re much more organized so that you know what to do next and then, simply, do that instead of wondering how to get to a specific goal.
When you use certain practices and tools, you will find bugs that you otherwise wouldn’t have found at all. And finding bugs is always good for profit!
Alright, with these in mind, let’s take a closer look at the details of each phase, thus saving your code from the apocalypse.
Communication
The one thing you will have to do all the time while working on your project is communicate.
Whether it’s about planning, fixing bugs, or monitoring your application, you really should talk to your team about all these aspects—and sometimes to your clients as well. And sometimes even to yourself …
Since it’s not possible to sit in the same office all the time, it’s great to still have a tool where you’re at least available most of the time or where you can check if anything interesting has happened.
Of course, there’s email, but there are definitely better solutions.
That’s where Slack comes in. In essence, Slack is a chat client. You can download and install Slack or use the web client.
Then you can create your own workspace for free and invite all your team members.
After that, you have your own little workspace for your project where you can create different channels for planning, talking about bugs, random chatter, and so on.
Additionally, you can integrate several services with Slack. For instance, if you’re deploying your application, you can automatically send a message into your Slack workspace where everyone can see whether the deployment succeeded or failed. That way you don’t have to watch the deployment process by yourself.
And Slack provides several more features like file transfer and video calls.
I’m not getting paid to say this (as with all the tools I recommend here), but Slack is really a great tool to help you during development.
You can start using Slack absolutely free. So I recommend you go to slack.com and register your workspace right now.
Plan
Planning is a topic you shouldn’t underestimate. It can make or break your project. This is particularly the case if you think you will implement some features on the side that might be put into your project management method of choice.
Have you ever heard of the waterfall model or the spiral model? These are more or less outdated, but it’s still interesting to know how software was developed in the past and … well, sometimes still today. But there are definitely better solutions nowadays.
As you can see below, the waterfall model provides several steps. Every single step should be finalized before you move to the next one.

Can you imagine having all the requirements ready and never talking about them anymore because they should be clear to everyone? Of course, this almost never really works. Same for the design or even the implementations. The waterfall model is highly unrealistic in the real world.
Sure, there has to be a concept, a document, with ideally all the features the application should have. But to expect that there won’t be any changes will get you into trouble. What are you going to say if the customer wants to change something or did not really know what a certain part of the software should look like? “Time’s up, we have to start from scratch again, and it’ll cost another fortune?” I bet you’ll never see that customer again.
The spiral model was definitely better and very similar to the agile processes that are mostly used nowadays.
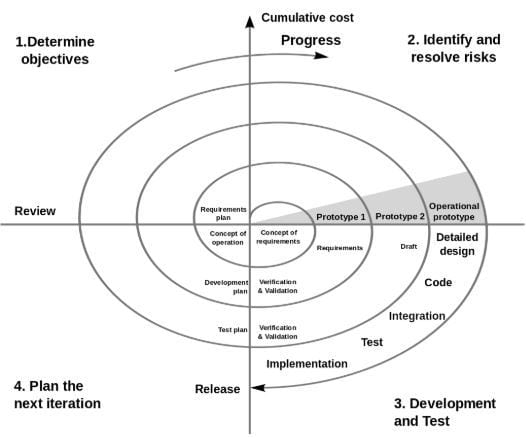
It’s all about iterations here. You manage your project in a way that you’ll go through each step many times. Again, it’s good to have a rough concept for the software, but details are discussed and implemented in the corresponding iteration. That’s also a great way to handle any change requests. You don’t have to start all over again.
So today, people use a similar approach, so-called agile development processes.
Here’s a quote from Wikipedia that describes agile software development pretty well: “It advocates adaptive planning, evolutionary development, early delivery, and continual improvement, and it encourages rapid and flexible response to change.”
So, being agile means that you’re able to react quickly to certain events like change requests or bugs.
Instead of planning the whole development process from A to Z like in the waterfall model, you look at your project on a weekly basis or maybe every two weeks.
Of course you have the big picture in mind, but it’s important to always look at the next cycle, the next iteration, or as they call it in Scrum—one of the software development frameworks mentioned here—the next Sprint.
These software development frameworks—Scrum or Kanban—help you keep using agile development processes. Let’s take a closer look at both of them, starting with Scrum.
Scrum

This is the scrum framework. It looks complicated, but don’t worry; there’s no need to examine every single detail. This paragraph should just give you an overview of how things work and how Scrum can improve your development cycle.
As you can see, on the far left you’ve got your product backlog. In essence these are all the tasks, all the features, simply everything your final product should have when it’s done. These tasks or features are given by the so called product owner. She’s talking to the customer or the stakeholders or simply has her own ideas for the project.
But instead of climbing this whole mountain of things to do at once, you want to move one step after another. That’s what the sprint planning is for. Again, a sprint is one iteration and is usually set for one or two weeks.
In the sprint planning meeting—which might rather be a sprint planning day—you plan all the tasks for the next sprint. The result of this meeting is the sprint backlog: all the tasks that you and your team commit doing in this iteration.
In a perfect world you really have to confirm the tasks that wander into this backlog, because you’ll have to do it, and only you can estimate the time it takes to finish them. At least in theory. But nothing happens if you cannot meet the deadline. Sometimes, problems occur or estimations have been wrong. Usually that’s no big deal. That’s what reviews, retrospectives, and new sprint plannings are for.
During a sprint, there are the daily scrums. This should be a daily meeting that is really short. Every team member is just telling in short, with no detail, what she was working on, what she is working on at the moment, and if there are any problems. If there are problems, then you’ll talk about them after the daily scrum. It really is just for checking the current state of development.
This daily scrum is held by the so-called scrum master. This person asks everybody for their current situation and, if necessary, assigns new tasks. If there are any issues or a team member needs support, the scrum master is the person to contact.
At the end of a sprint comes the review, which is in essence a user acceptance test. This means you show your results to the client or stakeholders or any person that has the right to see the results. Hopefully, these people accept your implementations.
After the sprint, you reflect on what went well and what did not in the sprint retrospective. It’s the perfect meeting to give feedback and suggest any improvements.
That’s it! The next iteration starts.
Again, this was really just a short overview. But it should give you an overall idea how this software development framework works.
Kanban
What’s Kanban? Actually kanban is a scheduling system for lean and just-in-time manufacturing. It was developed by an industrial engineer at Toyota to improve manufacturing efficiency. By the way, the Japanese word “kanban” means “visual signal.” Often times your actual work as a developer is invisible. Using Kanban makes it visible, and you can show it to others, and keep everyone on the same page.
Kanban was brought to the software development world by David Anderson with the kanban board.
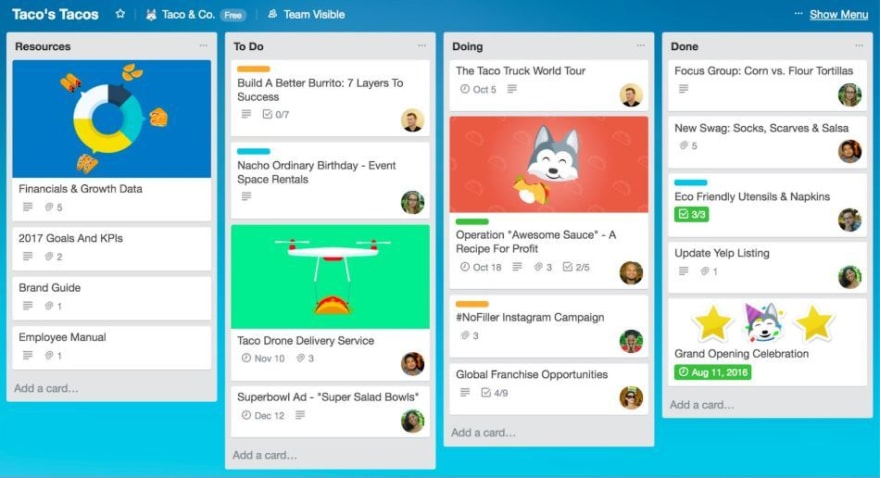
A kanban board is what you see above. It’s an example of the tool Trello. The board consists of columns and cards and wants to help your development team get stuff done! A card represents a task and a column a category or the current state of this task.
You can totally combine a kanban board with Scrum. As you can see, there is a column for ToDo cards, one for cards or tasks that you’re currently doing, and one column for finished tasks.
You could also add a backlog column. In that case you could add all your product backlog tasks into that column. Then, for the upcoming sprint, you move the tasks your team wants to do in the ToDo column. As soon as someone grabs a task from there, it will be moved to the Doing column, and so on. You get the idea.
Another great thing about Trello or a digital kanban board in general is that you can add more information to a card. You can add a description to your card, assign team members, and add a checklist, and you could also add images or write comments. This is very useful if you want to track any bugs in your application—add a screen shot with a description and the debugging can start.
It’s a simple but very efficient project management solution. Of course, there are big tools like asana, monday.com, Basecamp, and more. But a kanban board like Trello can absolutely be sufficient. Again, it’s just a recommendation from my experience.
Build
Now here’s where the actual work is happening.
I cannot really help you with the IDE you are using to write your actual code. There are lots and lots of choices.
I do recommend Visual Studio Code, though, with several extensions if that suits your needs. It’s definitely my favorite IDE for projects in .NET, JavaScript, and TypeScript. You can also use it for Java or Python projects with certain extensions, for instance.
But that’s not what the “Build” part is all about. It is more about managing your code. And for that, you definitely need source control. Now what is source control all about?
Source control means that you’re tracking and managing changes to code. But not only the code you are writing. It’s about the code of your whole team.
When you’re working on a project all by yourself, you might think you don’t really need source control. You might think you can manage your changes by backing up some files and that’s it. But I really recommend using source control even if you’re working as a one-man army. And even more if you’re working on a team, of course.
There are many benefits of using source control, like having a history of your changes, merging code changes of your team members, and creating feature branches.
Let’s elaborate on all that by the example of the source control system Git.
Source Control With Git
The source control or version control system that fits for most projects is Git.
Git was originally developed by Linus Torvalds, the guy who also created the Linux kernel. It will definitely help you to track and manage changes to your code, in particular when you’re working in a team.
So what does tracking and managing your code changes actually mean?
For starters, if you or one of your team members messed up, you can simply go back to a version of your application that worked. There have been times where people would copy and paste files from one machine to another and hope that everything worked. Believe me, I have been there. It was not a great time. Remember the shocked cat from before?
But not today. Today you have a so-called repository. Everybody in your team commits and pushes their code changes to this repository.

The screen shot you see above is a Git client, in this case called Fork. In essence, you see the Git repository here. You can see the whole history of commits. On the left you can also see that we’re looking at the master branch—let’s say it’s the main version of your code. We’re going to talk about branches in a minute.
When you commit your changes and you haven’t changed the same code someone else has changed, Git will automatically merge your code changes with the changes of your co-workers by itself. Isn’t that great? And it doesn’t even have to be different files.
Let’s say you and a co-worker are working on the same file but on different functions. Git will manage to merge your changes. No need to copy and paste that stuff anymore. (If you’re new to this, then this might be life-changing!)
If, however, you and one or more of your teammates have made changes to the same code, then you might get a merge conflict.
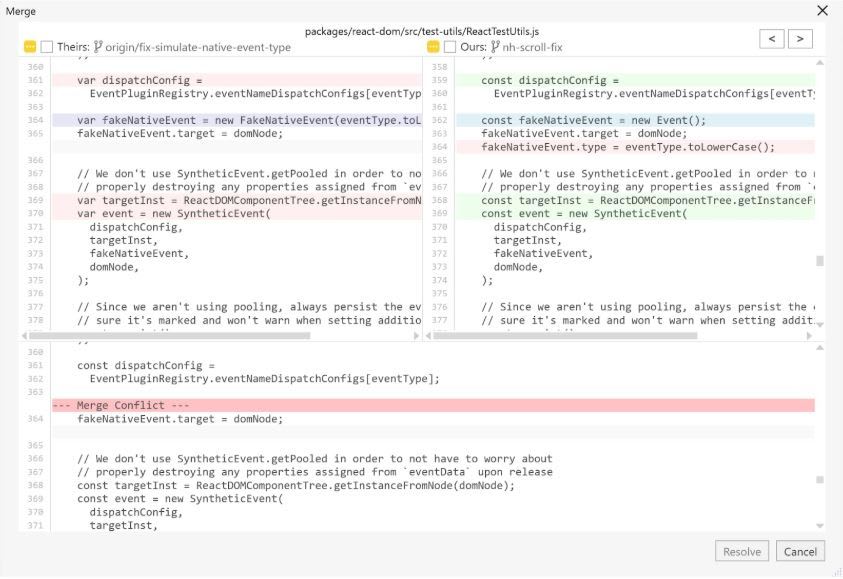
This means there are already committed changes to the same lines of code you wanted to change. In the screen shot, you can see that Git doesn’t know which version of the code it should choose. Their version or ours?
In this case, you have to resolve this conflict by yourself by either choosing one side, selecting both, or quickly fixing the conflict manually in the editor. There are tools that will help you to resolve conflicts.
Most IDEs, for instance, already manage to do that. So one of the tools might be Visual Studio Code itself. Other tools that are specifically made for Git are TortoiseGit or GitKraken. You have also already seen Fork and Sourcetree. Most Git clients are available for free or at least have a free trial version.
If you’re not a big fan of clients with a graphical user interface, you can also stick to the Git bash, a terminal, or the command prompt—depending on your operating system.
But to make this work, you first have to download Git for your operating system.
After you have downloaded Git, you can either create a repository on your machine or on a server or use one of the free services online and just clone the online created repository to your local machine.
Cloning means that you basically download the repository and that your changes will then be tracked. This way, you can commit and push them—meaning upload—again. We’ll look into these online services in the Continuous Integration section further below.
Whatever you choose, every team member can then use this repository and push changes to it. It’s a wonderful centralized solution.
But that’s not all! Another great thing about Git is the ability to create branches.
Now what are branches, sometimes also called feature branches?
You can grab the current code base and create a copy of the current state. Then make changes to the code and push your changes without touching the copied code base, often referred to as the master branch.
Let’s repeat this because it’s important: You make a copy of the master branch and change your code without touching the master branch. This is great if you want to create a new feature and push your changes for this feature without the risk of destroying the working code base. That way, your code is safe in the repository and not lying around on your hard disk.
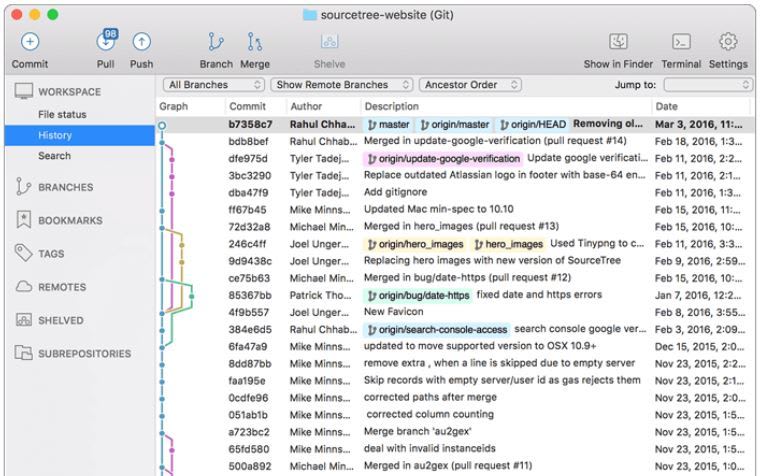
You see those colorful lines in the screen shot? These are different branches. Hero_images and google_verification are features that have been developed in their own branch, and after they were tested successfully, they have been merged back with the master branch, and your changes become part of the main code base.
If you don’t work that way, something like the following might happen:

These images have been taken from the trailer of the Sonic movie. Paramount published a trailer for this movie, and the community was not happy with it. You could say the first version represents code changes directly in the master branch without reviewing or testing them.
The second version was using a feature branch that has been tested and then merged into the master branch. Much better, don’t you think?
Containers
One more thing that will help you save your code from the apocalypse is Docker, or containers in general.
Let’s have a look at this quote from Wikipedia:
Docker can package an application and its dependencies in a virtual container that can run on any Linux server. This helps provide flexibility and portability enabling the application to be run in various locations, whether on-premises, in a public cloud, or in a private cloud. Docker […] allow[s] containers to run within a single Linux instance, avoiding the overhead of starting and maintaining virtual machines.
Put simply, with Docker, you can fire up a kind of virtual machine that grabs everything you need (libraries, etc.) to run your application and just, well, run it.
That way, you can test your application real quick every single time you make changes and tell for sure that your application not only runs on your machine but also on a completely fresh system. Maybe you want to have a look into that eventually. It might increase your productivity even more.
Continuous Integration
Continuous Integration is big and really useful. But what is it all about anyway?
I think this short description taken from GitLab describes it pretty well.
Continuous Integration is the practice of integrating code into a shared repository and building/testing each change automatically, as early as possible—usually several times a day.
I already referred to this in the Source Control With Git section. Every day you and your teammates work on a project, you might want to commit and push your changes to the code base several times a day.
Without a repository and without continuous integration, you would have to merge the whole code manually—again, several times a day. That would be really time consuming. So you would rather merge your code only once a day, once a week, or even just once a month. This causes lots of problems or at least annoying tasks.
With continuous integration and source control, this stuff is history.
You got your repository, you check your code in, and you don’t have to bother with this administrative work anymore.

Continuous Integration
This image shows what the usual process of developing your software can look like. In the quote from GitLab, they mentioned tests—more precisely it’s about automated tests.
You build your application; after pushing your changes, automated tests will be run; and if they succeed, your app will be deployed to your server, to the cloud, you name it.
Automated tests seem to be the operative element here, so let’s take a closer look
Automated Tests
The most known automated tests are unit tests and integration tests—together with test-driven development, but that’s another kind of development practice, which is outside the present scope.
Take unit tests for instance. As the name already implies, you want to test single units with these tests. Imagine you have a calculator, and you just want to test whether the addition or subtraction works. Then you write tests for only that part.
After you’ve done these tests, you might want to test whether all these units also work together. Is it possible to subtract and add numbers in one calculation? That would be an integration test.
Another example is to write unit tests for back end code but also write integration tests to see if the front end properly works together with the back end.
If you only use unit tests and leave the integration tests, something like that can happen:

You see, the sliding doors and the swing shopping gate work perfectly, but not together. Somebody definitely forgot to do some integration tests here.

As always, there are a bunch of testing frameworks you can use. Above is an example of the Microsoft Testing Framework. In Visual Studio you can see which test failed and which test was successful. If a test fails, you can also have a deeper look and find out what went wrong. Is it your implementation of the unit, or did you write a wrong test?
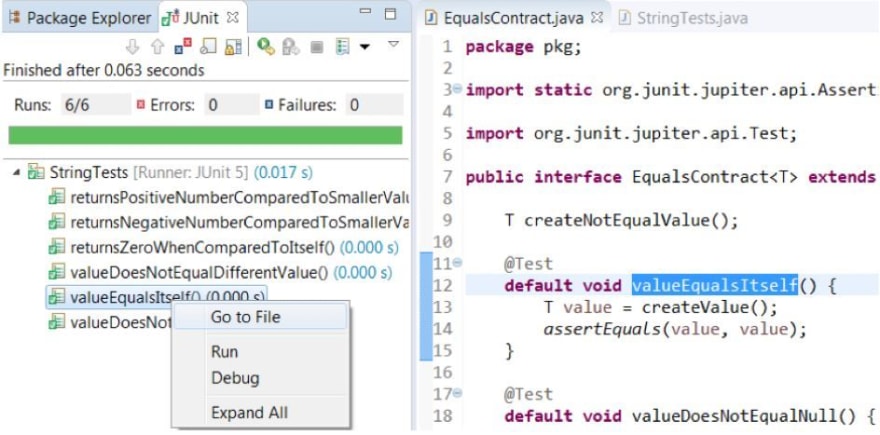
If you’re in the Java world, JUnit with Eclipse looks quite similar. Test results are on the left side, details or implementations on the right. You can also see that test implementations have their own annotations. So, there are specific rules on how to write your test and how to work with a particular testing framework.
Whatever you’re writing your software with, there will be a testing framework. Just look around. Angular on the front end already has its own test files, for instance.
Automated tests fit perfectly into the continuous integration process, but you don’t have to use them. Just remember, the idea behind continuous integration is that you write your code, push it to your source control repository, your app will be built or compiled on a server, the tests will be run, and after all tests have passed, your application will be deployed.
Continuous Integration Services

There are several services you can use for continuous integration. Some can do more, some less. Jenkins is one of the leading automation servers, for instance. But for your case, other solutions might be better.
In my experience, Jenkins and Hudson do a great job on continuous integration, and you can add more features through extensions. But there are also other platforms that provide complete DevOps solutions.
GitLab, Bitbucket or Azure DevOps (which even uses the DevOps term) want to be all-in-one solutions—and in my experience, they really are. Not only do you get continuous integration, you also get a repository, issue boards, ticketing, deployment solutions, notifications, lots of integration options with other tools, and so on.
Don’t get me wrong. The other services can do this, too, but you might have more work setting things up.
In the end, it’s for you to decide which service, tool, or platform you want to use. The best way to decide is to simply try them out and find the one that you like the most and that fits your requirements.
Continuous Integration Configuration
But let’s have a look at how you make continuous integration work on the example of GitLab.
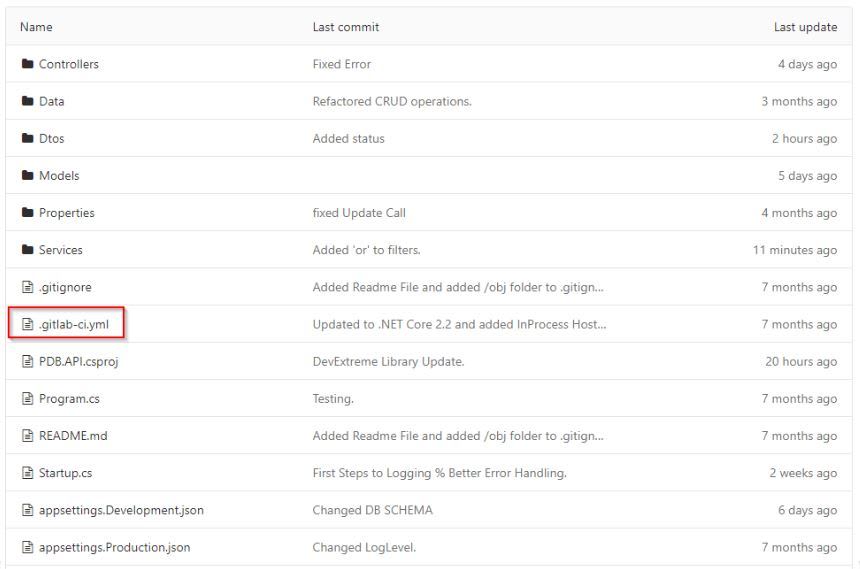
The first thing you need is a configurations file. In the case of GitLab, it’s a yml file, called .gitlab-ci.yml.
You see that it’s just put into the root directory of your project.
This yml file consists of a script. You can define stages and then add commands for every stage or commands for the moment before or after a certain stage.
In these examples you see deployment scripts for a .NET Core back end and an Angular front end.
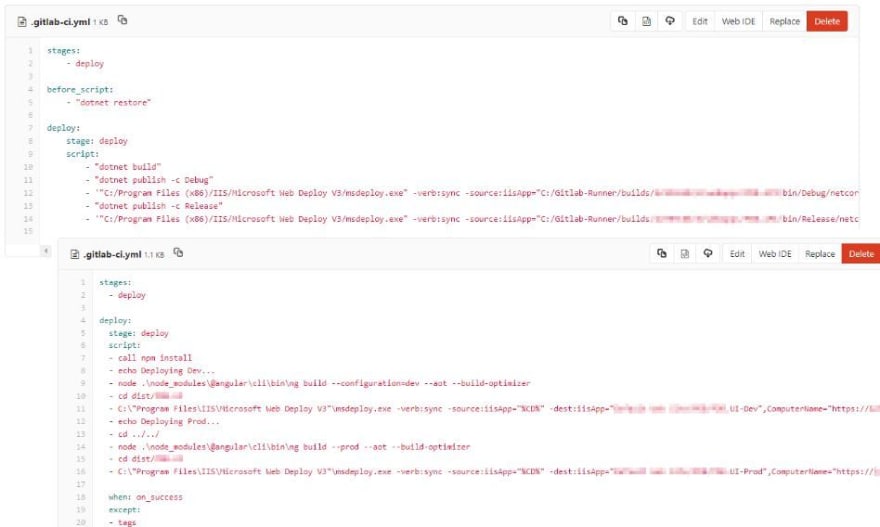
In essence, you just enter the commands you would also run when you want to build your application locally on your development machine. And then you add commands to publish the compiled application.
For example, in the .NET Core case, we run the dotnet build and the dotnet publish commands to publish the debug and release version. Regarding Angular, we call npm install to install all dependencies and then run ng build with specific configurations. Both applications, the back end service and the Angular front end, are deployed to Internet Information Services on a Windows Server.
One beautiful advantage of this is that you build the code every time like it’s the first time. Ideally, in case of an error, you never hear the phrase “but it’s running on my machine” again.
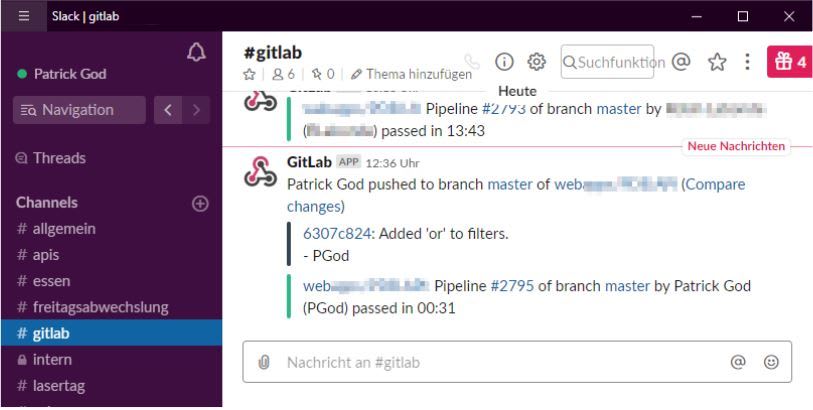
As mentioned earlier, there are ways to integrate a DevOps platform like GitLab with other tools like Slack. As soon as code was pushed or a build and deployment process has been finished, a message will be sent to a Slack channel. It will also add the commit message and the result of the deployment.
From there I can click on “Compare changes” or on the pipeline number of the deployment process.
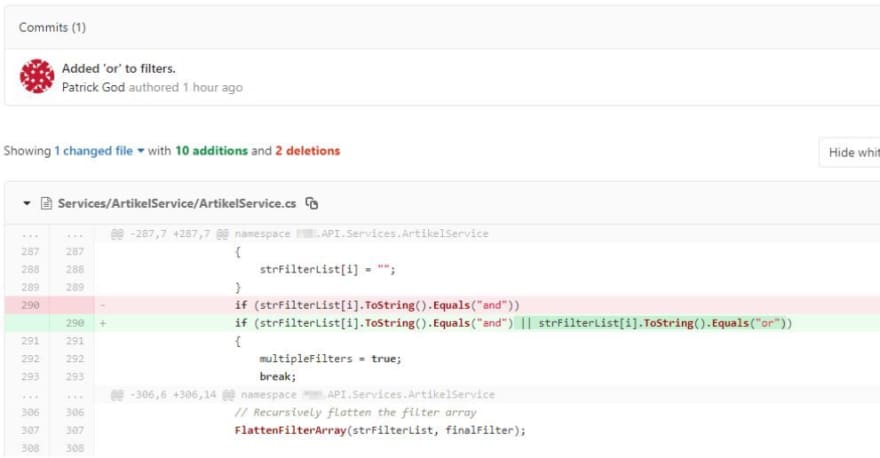
“Compare changes” brings me to the actual commit where I can, well, compare the code changes. In this example you see the changed file with all the differences to the previous version of this file, like the added condition in line 290.
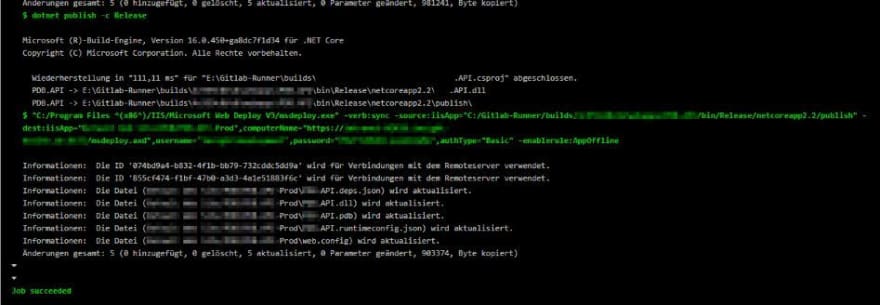
Clicking on the pipeline brings me to the result of the yml script. You see the commands like dotnet publish and the results of these commands. If anything went wrong, you would see the concrete error here, hopefully with hints on how to fix it. If everything went well, you see the “Job succeeded” statement.
That’s how continuous integration works. The code will be integrated in a shared repository; it will be built and tested automatically, several times a day.
We can even go a bit further with continuous deployment or delivery.
Continuous delivery adds that the software can be released to production at any time, often by automatically pushing changes to a staging system.
Continuous deployment goes even further and pushes changes to production automatically.
In essence, this means that you would not only build and test your code, but you would also deploy it to your running production server for that application. No need for manually moving your test or staging version to your production server. DevOps can do all this for you automatically.
Remember the cat on the beach? That’s how we’re getting there.
Deploy
We already talked about deployment while covering continuous integration.
Deployment is the process that moves your code to a server or platform where people can actually use it.

There are several ways to do this. You can rent your own dedicated server or a virtual machine or you use one of the many available platforms like Microsoft Azure, Amazon Web Services, or Google Cloud.
The big advantage of these three is that you don’t need to host and configure your own server. You just pay for what you actually need. You need a database and a little webspace for your web application? Great, just add these, decide how much memory and what processor you want, and you’re done.
Another great thing about these platforms is the option of scaling. If you need more power only for a short period of time, you can add more memory or anything else just for that period. If your application or user count grows, you can also scale for a longer-term.
When you have to rely on a server you manage by yourself, you might have to buy another one additionally or even migrate your application completely.
With GitLab and Bitbucket, you have great DevOps solutions, but you might have to get a server yourself, where your application will then be deployed to.
Of course, services like Microsoft Azure cost money. But, there are free options available, too. In this case, you can test the service for 12 months. You can test and deploy apps to virtual machines and use SQL databases, for instance.
Mobile apps are also no problem at all, and another great advantage, with a service like Azure, you are able to gain insights from your user data and maybe improve your application and user experience based on that data.
Amazon Web Services is quite similar. There are also free options available, but they are separated in tiers. Some services are free forever, some you can test for 12 months, and others have a more limited trial time like 30 days. But again, you can add just the service you need.
The Google Cloud platform takes a different approach. Here you get a budget of 300 USD, which you can use to build and access anything you want. It’s great that you can also use special Google services and APIs like Firebase or the Google Maps API.
It’s important to note that you won’t get charged any fees automatically after your free trials ends. You have to upgrade to a paid plan by yourself first. This is really nice and customer friendly.
Bitbucket and GitLab look a bit different. There are free plans available as well, and I think, in most cases they are totally sufficient if you’re just starting out.
There’s a typical pricing model for Bitbucket. There are certain features available for free for a small team, including unlimited private repositories, a Trello integration, and continuous integration. If your team grows or you need more features, you have to upgrade to a paid plan.
Again, GitLab is quite similar. In the free plan, you already get unlimited repositories, continuous integration, and lots of integration options, too. It seems that it’s not limited to the size of your team.
With the paid plans, you simply get more and more features.
In the end it is up to you. What do you need? I recommend you compare the services, maybe start with a free plan, maybe even a service with limited features just to get the hang of it, and then switch to something bigger when you need it and when you’re more familiar with all the different features these platforms and services have to offer.
Operate

The next phase in the DevOps circle would be operating. Or in other words, monitoring your servers, logging information and occurring errors, and sending notifications if necessary.
Again, there are a bunch of services available that can help you with all that. Nagios, Loggly, dynatrace, and splunk might be some services you want to have a look at.
Nagios is all about monitoring. It can monitor your Windows or Linux system, any kind of server, your applications, and so on, and it will log the results of monitoring all this.
And, of course, there is a free trial available.
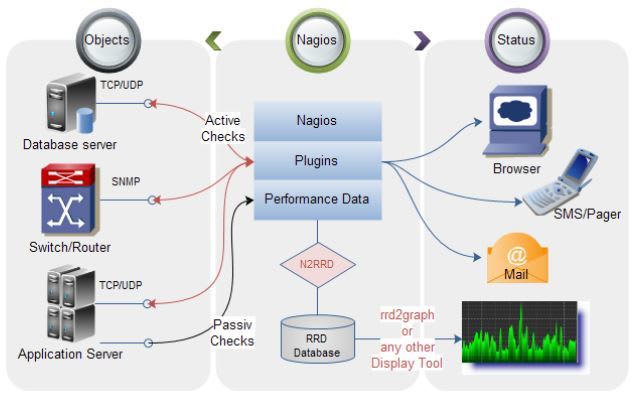
Here’s a structure of what working with Nagios might look like.
You have your objects on the left. These are usually any kind of servers. Nagios can then check whether everything is up and running and working as it’s supposed to work. It can also track performance data.
Then we have the status column on the right. This simply means that Nagios is able to send notification to you whenever and wherever you want them. So if, for instance, an error occurs, you can tell Nagios to send an email or SMS, or you can simply log it into a database or web application where you can check for these errors by yourself.
Again, everything is done automatically, and you don’t have to watch your servers the whole time by yourself.
Dynatrace is taking a different approach. They advertise their services with an AI-powered, all-in-one plattform. Instead of just monitoring and delivering data, they want to also provide interpretations and “answers” to your data. A free trial is also available here.
But for me the big question is, do you really need a service like this? Mostly, this kind of monitoring is necessary for medium to large companies. In most cases, you can try doing some logging and sending notifications by yourself but still automated.
Why not just write a logging service in your back end by yourself? You could write any information you want into a database or even a text file, and if any errors occur or exceptions are thrown, just send an email to yourself or to the development team with certain information like the date and time, the user triggering the error, and the request data.
You can then have a deeper look into the log, try to reproduce the error, fix it, and you’re done.
Feedback
We are slowly coming to an end of the DevOps circle with the last phase, feedback.
Feedback comes in different ways. We have automated status updates, IT service management (ITSM), customer relationship management (CRM) and bug tracking.
Put simply, we can say that ITSM focuses more on feedback for IT departments, whereas CRM focuses on the customer. Issue tracking can be a part of IT service management. But let’s have a look at some of these services first.

Feedback Services
We have services and platforms for IT service management, customer relationship management, and issue tracking here.
Some services are more relevant for customer relationship management. This means they focus on storing information about customers and providing them feedback, and hopefully, they result in increased profit. Because when you’re able to track customer information and give them the right feedback, your customers might be happier, buy more often, and recommend your services.
But I want to focus on IT service management or, more precisely, issue or bug tracking. Mantis, Bugzilla, Jira, and Trello are web applications that provide the option to write tickets and bug reports. Mantis and Bugzilla focus more on tracking bugs.
The purpose of an issue tracker like Mantis is to provide the option to add a description of issues in your application to said tracker. So as soon as an error occurs, you or a tester of your application adds a new issue with a title, a description of what happened, and maybe also what consequences this issue had. Did the app crash, did this bug just result in a strange UI behaviour, or anything else?
With Mantis or Bugzilla, you have a tracker that enables your whole team to collaborate and watch all bugs in your application.
As almost always, you can start a free trial or even have a sneak peek at the service. Because the official tracker of Mantis itself is open to everyone.
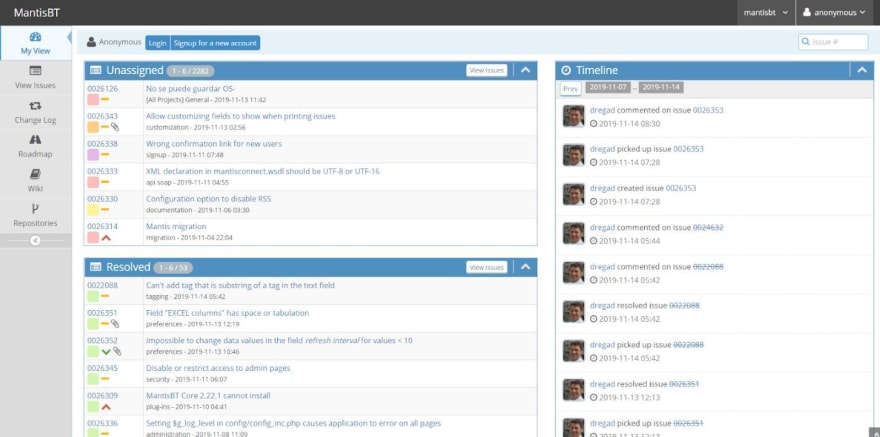
As you can see, we have a list of several issues. Some are unassigned, some are resolved, you can see a timeline of issues that have been created, edited, or commented on, and you can also view all the issues in detail.
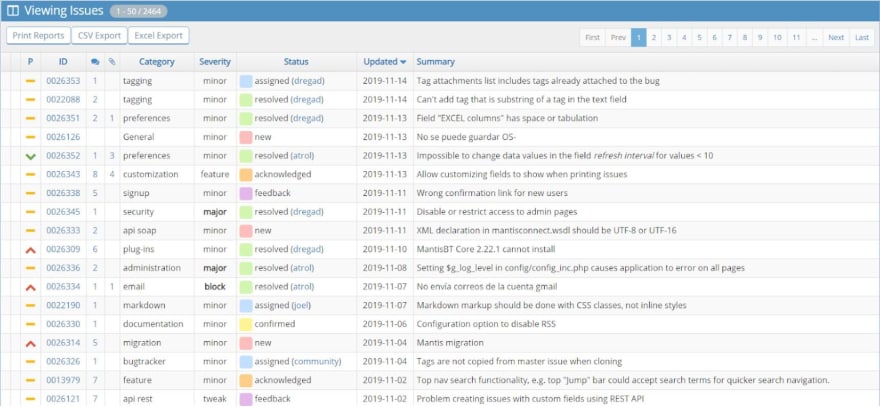
Then you see properties like the severity, status, or the category of every issue. Of course you also see the date of the last update and the summary of what this issue is all about.
That way you hopefully get your bugs organized, and it will help you to make your software better. Additionally, with enabled notification, your team will know what’s going on all the time.
For instance, if a team member fixes a bug, the reporter of this bug can get a notification and already test the fix. Because thanks to continuous integration and delivery, the code with the fixed bug is already published and deployed to your test system, right? Great stuff!
Jira
Jira is just another example of that kind of software. But where Mantis focuses on bugs alone, Jira is usually also used for feature requests or any kind of tickets in general. But the core functionality is the same. Create tickets, track them, update them, finish them, and send notifications.
GitLab Issue Board
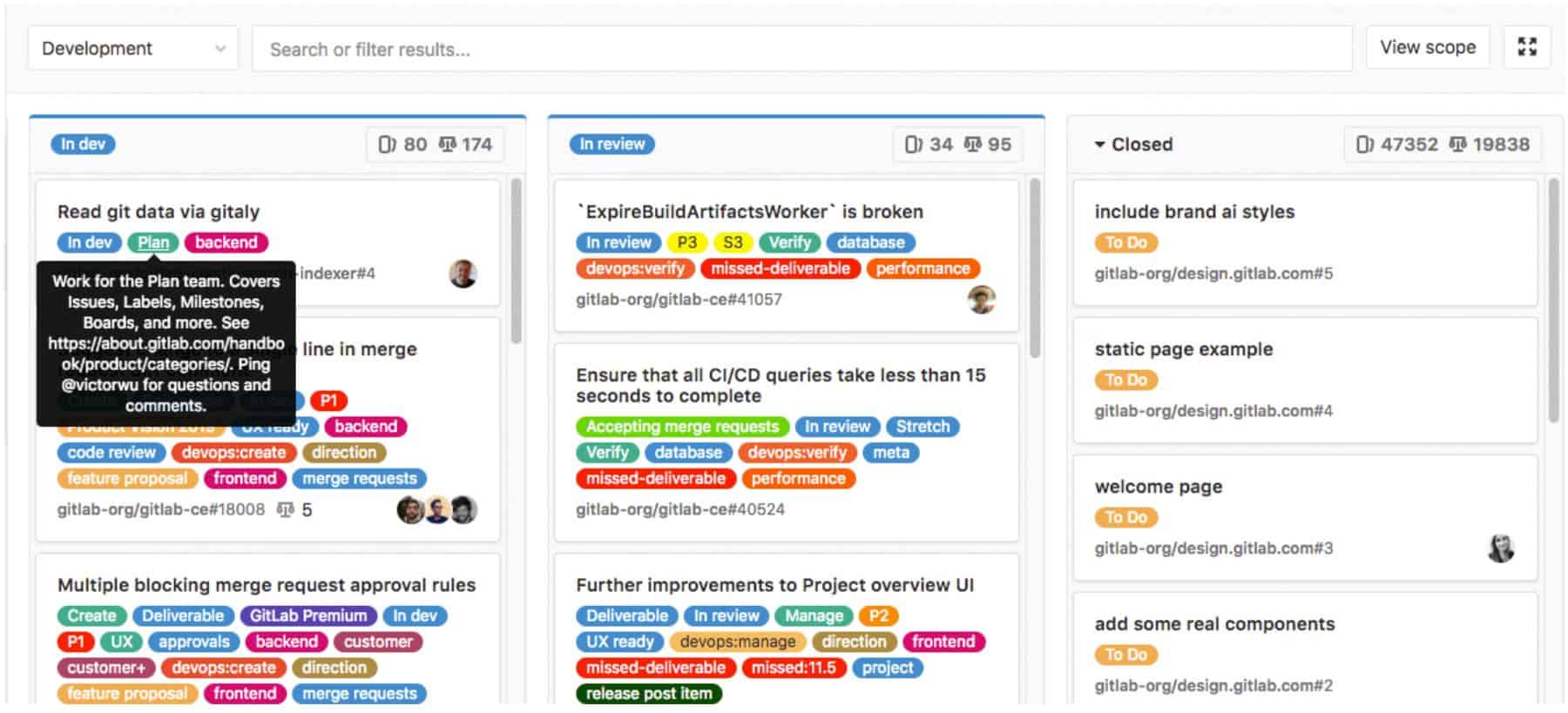
GitLab provides an issue tracking feature as well. You can even decide for yourself if you want to see the tickets or issues as a list or as a board. You can also add categories, severities, different colors, and so on. And this looks really similar to Trello.
And where do we find Trello again? In the planning phase, so right in the beginning of our DevOps circle. Issue trackers like Mantis might look different, but actually you could totally use the software you’re using to plan your development lifecycle to also track your issues.
If you’re using a DevOps solutions platform like GitLab, you don’t even need an additional tool.
You see where I’m going with this? We’ve come full circle. Giving and providing feedback results in planning your next iteration.
Save Your Code, Be a Happy Cat
So we’ve come full circle now. We went from planning to building, then to continuous integration and deployment, and then we entered the Ops part of DevOps where it’s about operating and feedback. Based on that feedback, we are able to plan the next step of development. All this is surrounded by real-time communication.
You’ve seen lots and lots of tools that can help you in every single stage of DevOps. What you use is totally up to you. Choose a tool for every single step, do things by yourself like logging exceptions and sending emails to your team, or grab one of the big DevOps platforms and do everything with one single service.
Just remember to implement DevOps in your software development life cycle. You don’t want to look like the shocked cat in the beginning, do you?
Try out different tools, and then find a way that suits you best. There are so many solutions out there that I think there is a right way for every team, every company, and every kind of software you want to build.
I hope you learned something and you got some new insights. If you have any questions, feel free to ask!
Good Code Isn’t What Gets You Paid
The developers landing the senior roles and the consulting offers aren’t better engineers than you. They’re known. RDU is John’s coaching program for developers who are done being the best-kept secret on the team.
Book Your Free Call →
Related Articles

7 Ways to Prevent Daily Burnout as a Programmer
It’s important to prevent daily burnout as a programmer, especially because the job can be quite overwhelming at times. Here’s…

How To Develop an Effective Software Development Life Cycle
The early 1940s to 1960s was the beginning of the era of the information system and its development. Before that,…

Tips To Create an Effective Agile Communication Plan
In software development, many technological experts consider it essential to follow the agile methodology, which is a continuous iterative process…