If you are following backend development or Big Data fields, you’ve probably noticed that for the last couple of years, there has been a lot of hype about NoSQL databases. While some people seem to be very passionate about them, others may think that they are a gimmick: They have different, unusual data models, unfamiliar application programming interfaces, and sometimes unclear applications.
In this article, I will describe why NoSQL databases were created in the first place, what problems they solve, and why suddenly we need to have so many different databases.
If you are new to NoSQL, you may be especially interested in the last part of the article where I list what NoSQL databases you should learn first to get a 360-degree view of this area.
Why do we suddenly need a new database?
According to some predictions, in 2018 humanity as a whole will generate 50,000 GB of data per second. This is a tremendous amount of data, and storing and processing it is a serious engineering challenge. What is even scarier is this number is constantly growing.
Relational databases are ill-equipped to work with these amounts of data. They are designed to run a single machine and if you need to handle more requests, you have only one option: Buy a bigger computer with more memory and a better CPU. Unfortunately, there is a limit to how many requests a single machine can handle, and we need a different database technology that can run on multiple machines.
Now, some of you may scoff, and say that there are two widespread techniques of how you can use multiple machines if you use a relational database: replication and sharding. But they are not sufficient methods to handle challenges that we are facing.
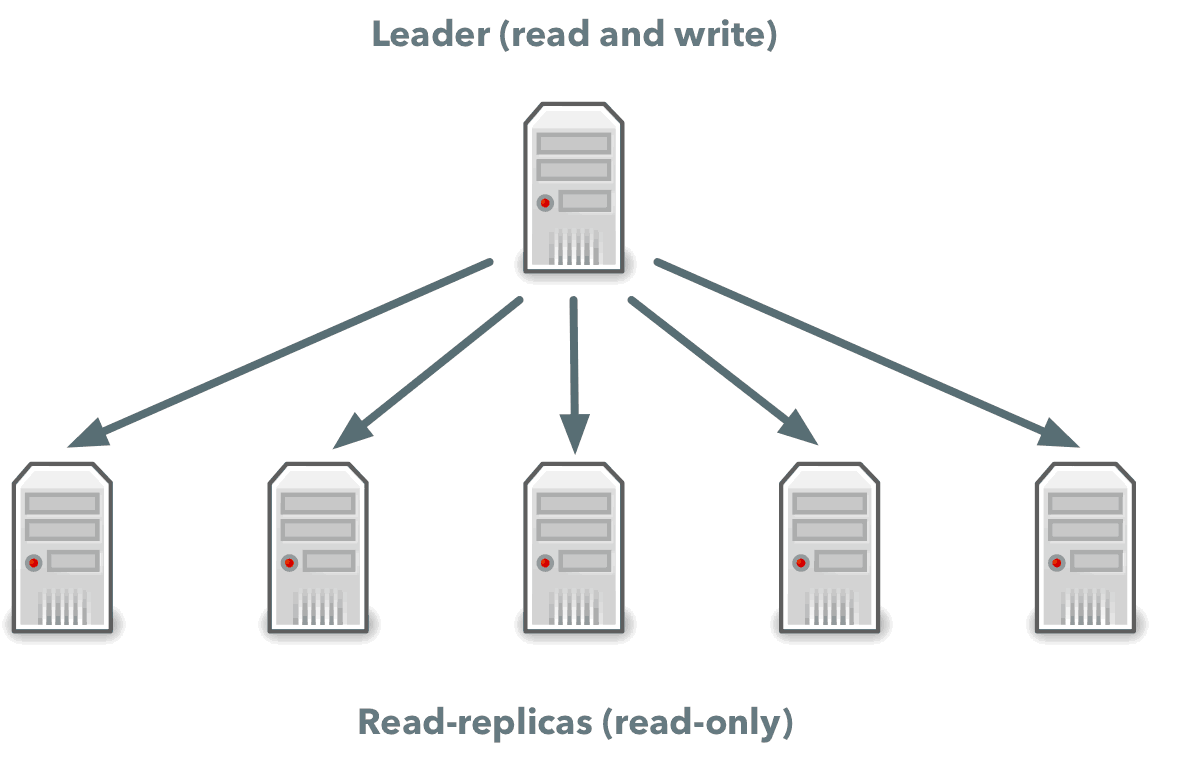
Read replication is a technique in which every update to your database is propagated to other hosts that can handle only read requests. In this case, all changes are applied by a single host, called the leader, while all other hosts, called read replicas, maintain a copy of the data. A user can read from any machine, but can change data only through the leader host. This is a useful and very popular technique, but it allows only handling of more read requests and doesn’t solve the problem of handling the required amount of incoming data.
Sharding is another popular technique where you have many relational database instances, and every instance accepts reads and writes for a part of your data. If you store information about a customer in your database, with sharding, one machine may process all requests for customers whose names start with A, another will store all the data for customers whose names start with B, and so on.
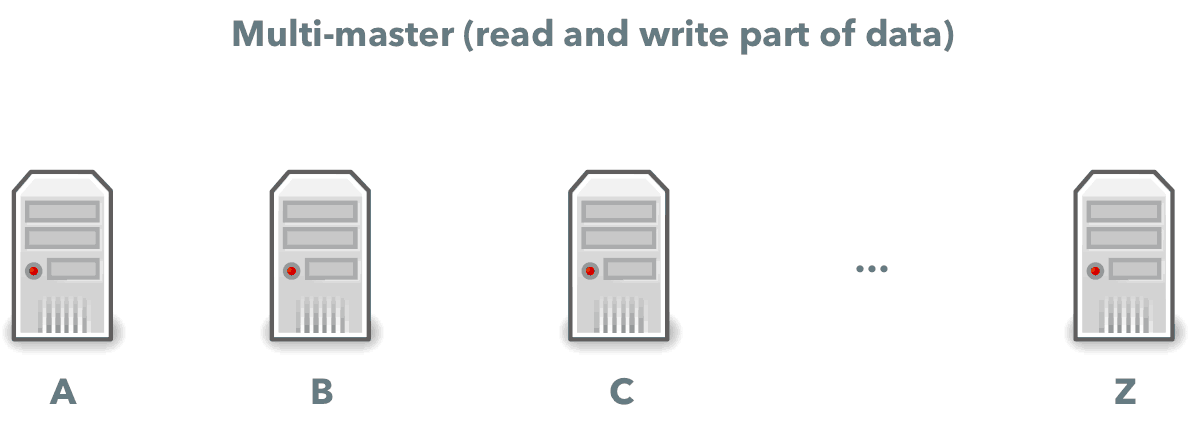
While sharding allows you to write more data, managing a sharded database can be a nightmare. You have to balance data across machines and scale your cluster up and down when necessary. While it may look simple in theory, implementing it correctly is a major challenge.
Can we have a better relational database?
I hope that by now, you see that relational databases can’t handle the amount of data that we generate, but you may still be left wondering why someone can’t build a better relational database that can run on multiple machines. You might think that the technology is simply not there yet and we will soon enjoy a distributed relational database.
Unfortunately, though, this will never happen because it is mathematically impossible, and we can do nothing about it.
To understand why this is the case, it’s important to talk about the so-called CAP theorem. The CAP theorem, which was proven in 1999, states that any distributed database running on multiple machines can have these three properties:
- Consistency – If you write data into a system, you should be able to read it back immediately afterward. If our system is consistent, after you write new data, you cannot read old, overwritten data.
- Availability – A distributed system can always serve incoming requests and return a non-error reply.
- Partition tolerance – A database will continue to reply to read and write requests even if some hosts cannot temporarily communicate with each other. This temporary hiccup is called a network partition and it can be caused by a number of factors, from actual problems with an underlying network from a slow host to physical damage to network equipment.
All these features are obviously useful and we would like to have all three. No one in their right mind would want to get rid of, say, availability without getting anything in return. Unfortunately, the CAP theorem also states that we cannot achieve all three properties in one system.
It may be a bit tricky to understand, but here is how you can think about it. First, if we want to have a distributed database, it should support “partition tolerance.” It’s not negotiable. Partitions happen all the time, and our database should work despite them.
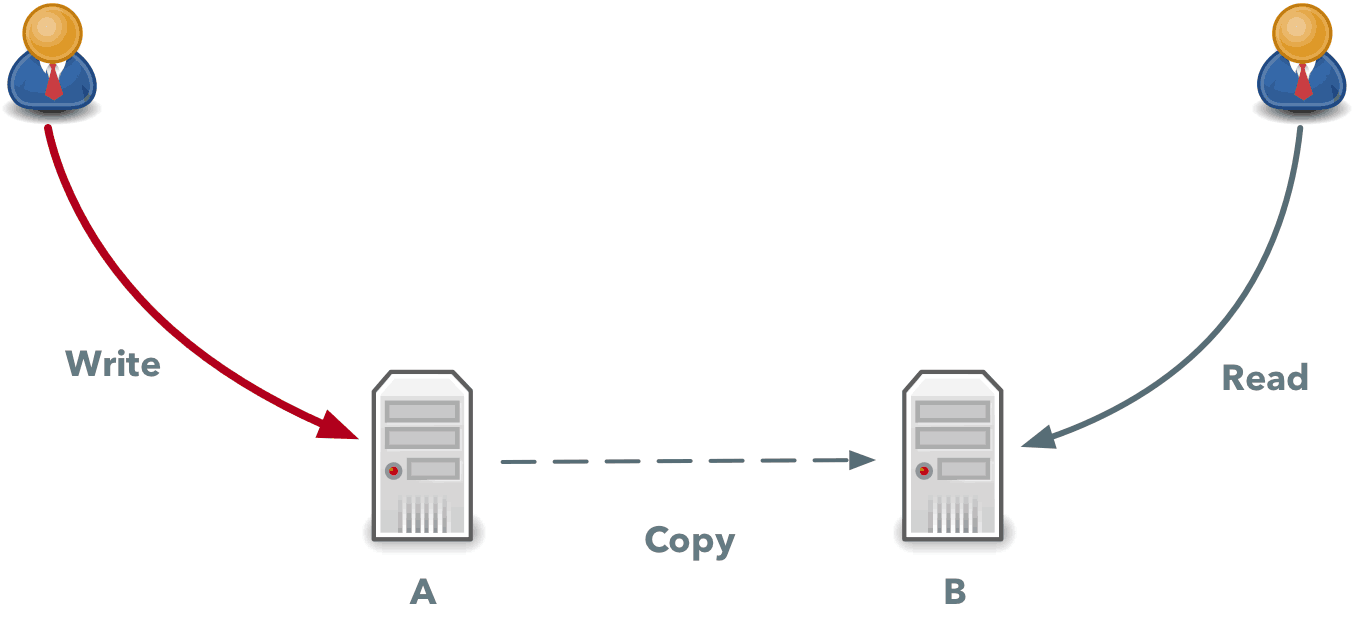
Now let’s see why we can’t have both consistency and availability at the same time. Imagine we have a simple database that runs on two machines: A and B. Any user of this database can write to any machine and then the copy is propagated to a second host.
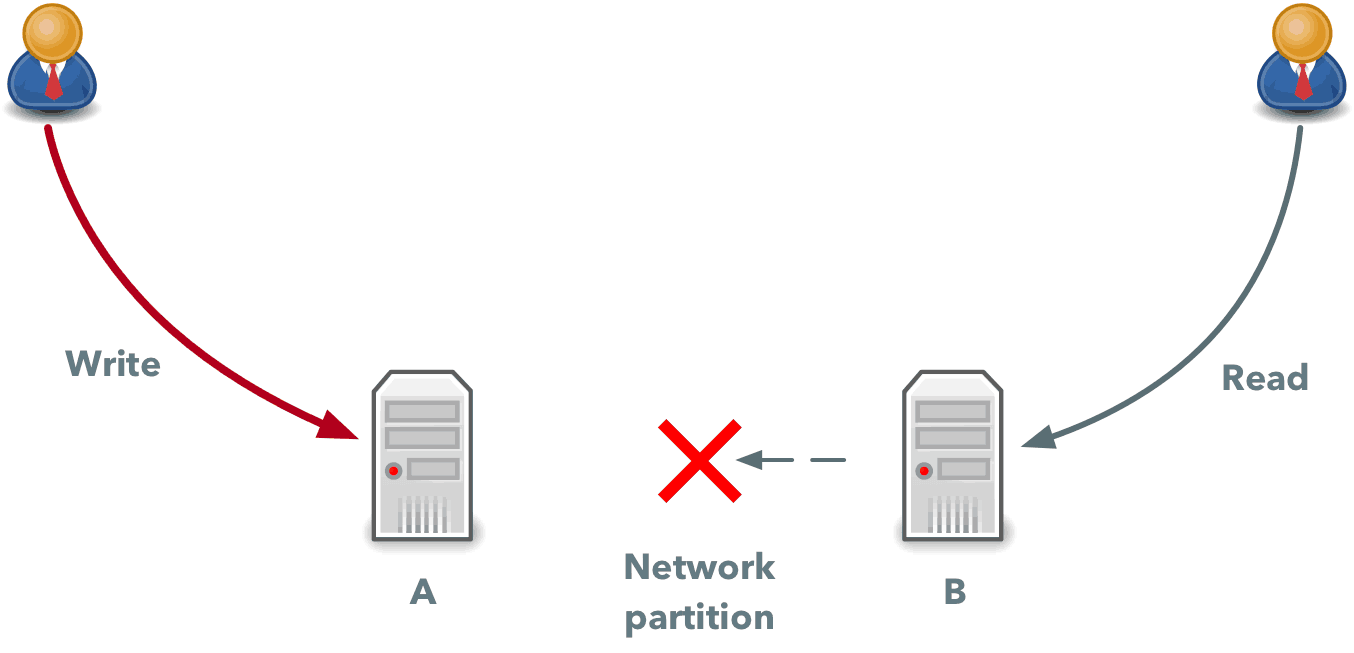
Now imagine that temporarily, these machines can’t communicate with each other and machine B cannot send to and receive data from machine A. If during this time, machine B receives a read request from a client, it has two options:
- Return its local data even if this is not the latest data. In this case, it will select availability (return some data that may be stale).
- Return an error. In this case, it will select consistency; the client won’t see stale data, but they also won’t get any data at all.
Relational databases try to implement both “consistency” and “availability” properties, and hence they can’t work in a distributed environment. If one would try to implement all features of a relational database, in a distributed system it would be either impractical (enormous latencies even for common operations) or simply impossible.
NoSQL databases, on the other hand, prioritize scalability and performance. They usually don’t have such “basic” features such as joins and transactions and do have a different, maybe even limiting data model. All this allows for storing more data and processing more requests than ever before.
How does NoSQL combine consistency and availability in one database?
At this point, you may be under the impression that if you select a NoSQL database, it either always returns some stale data or returns errors if any minor hiccup occurs. In practice, availability and consistency are not binary options. There is a broad spectrum of options that you can choose from.
Relational databases do not have these parameters, but NoSQL databases give you this control to select how your query should be executed. In one way or another, they allow you to specify two parameters when you perform a read or write operation with a NoSQL database:
- W – how many machines in a cluster should acknowledge that they have stored your data when you perform a write. The more machines you write data to, the easier it is to read the latest data with the next read, but the more time will it take.
- R – from how many machines you want to read data. In a distributed system, it may take some time for data to propagate to all machines in the cluster, so some hosts can have the latest data, while some can still lag behind. The more machines you read data from, the higher your chances of reading the latest data.
Let’s get more practical. If you have five machines in your cluster and you decide to write data to only one machine and then read data from one random machine, you have an 80 percent chance that you will get stale data. On the other hand, you will use a minimum amount of resources and if you can temporary tolerate stale data, you can choose this option. In this case, the W parameter is equal to 1 and R is equal to 1 as well.
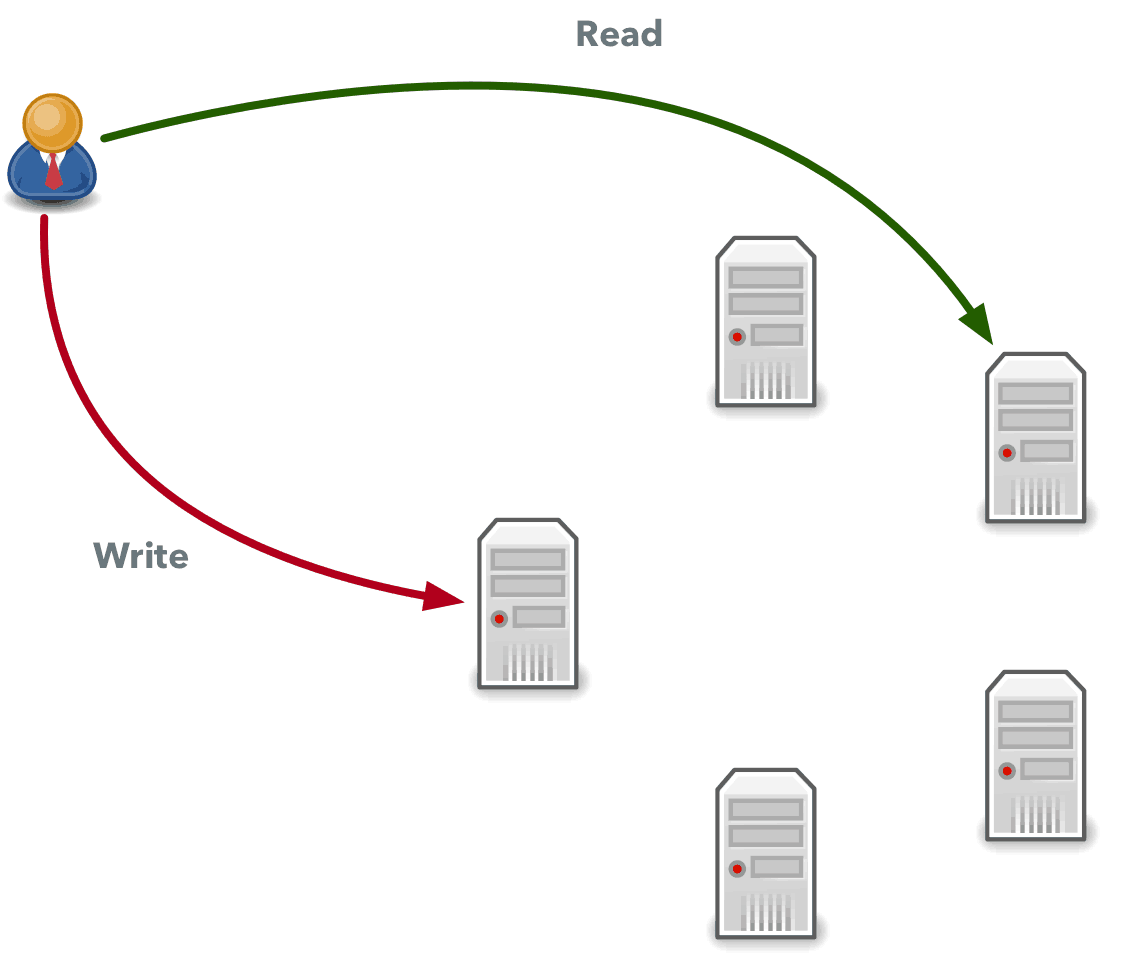
On the other hand, if you write data to all five machines in a NoSQL database, at once you can read data from any machine and it is guaranteed that you will get the latest data every single time. It will take longer to perform the same operation with more machines, but if it is important for you, you can do this. In this case, W=5 and R=5.
What are the minimal numbers of reads and writes we need to perform to have a consistent database? Here is a simple formula: R + W ≥ N + 1, where N is the number of machines in the cluster. It means that if we have five hosts, we can select either R=2 and W=4, R=3 and W=3, or R=4 and W=2. In this case, no matter what machines you write to, you will always read from at least one machine that has the latest data.
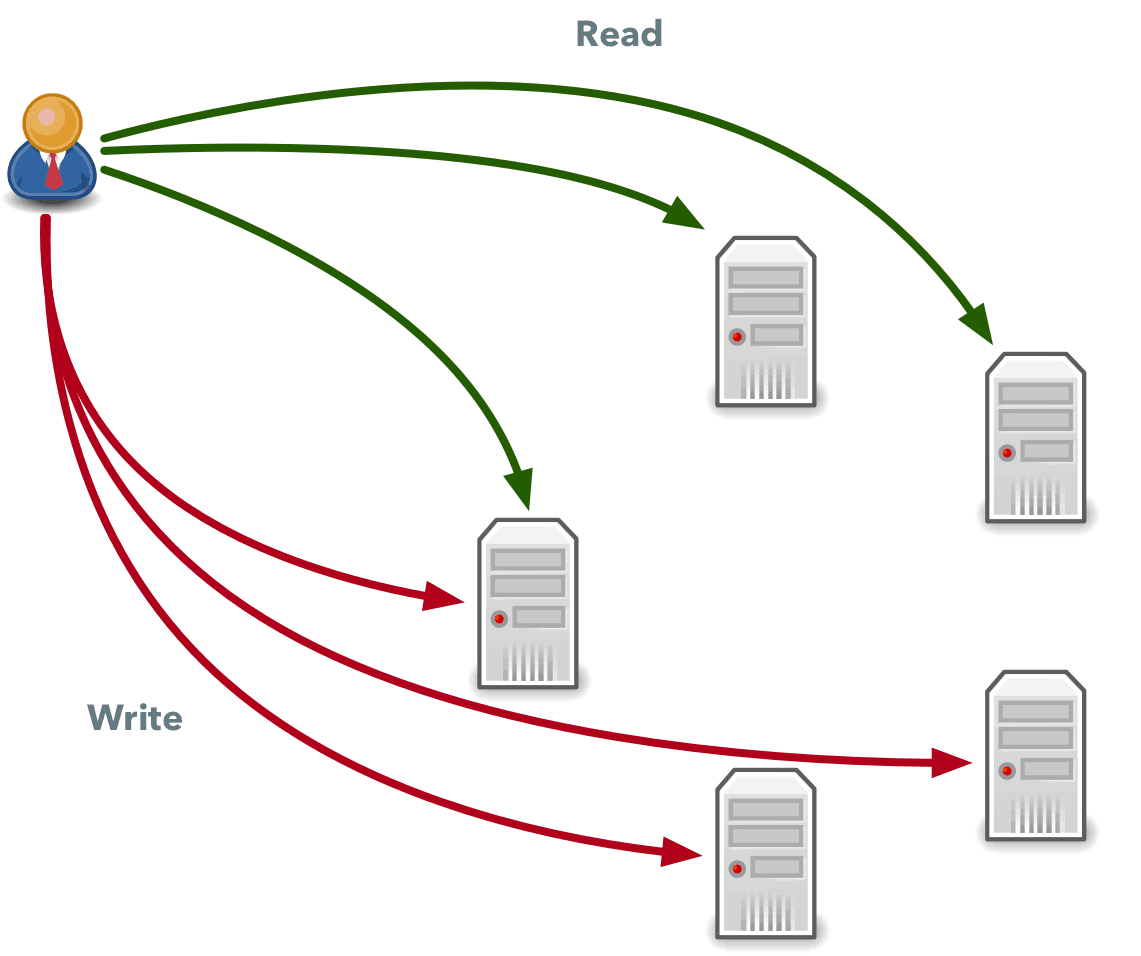
Other databases such as DynamoDB have other constraints and allow only consistent writes. Every data item is stored on three hosts, and when you write any data, it is written to two machines out of three. But if you read data, you can select one of the following:
- Strongly consistent read that will read data from two machines out of three and should always return the latest written data.
- Eventually consistent read that will pick one machine at random and read data from it. This, however, can temporarily return stale data.
Why are there so many NoSQL databases?
If you been following software development news, you’ve heard about many different NoSQL databases such as MongoDB, DynamoDB, Cassandra, Redis, and many more. You may now wonder why we need so many different NoSQL databases. The reason is that different NoSQL databases focus on solving different problems and that’s why we have such a large number of competitors. The taxonomy of NoSQL databases contains four main categories:
Document-oriented Databases
These databases allow storing of complex nested documents, while most relational databases support only one-dimensional rows. It can be useful in many cases, for example, if you want to store information about a user in your system and allow every user to have multiple addresses. Using a document-oriented database, you can simply store a complex object with an array of addresses in it, while a relational database forces you to create two tables: one for user information and another one for addresses.
Document-oriented databases allow you to bridge the gap between the object model and a data model of a database. Some relational databases such as PostgreSQL now also support document-oriented storage, but most relational databases still don’t have this feature.
Key-value Databases
Key-value databases usually implement the simplest NoSQL model. At their core, they provide you with a distributed hash table that allows you to write data for a specified key and read back data using this key.
Key-value databases are easily scalable and have a much lower latency than other databases.
Graph Databases
Many domains, such as social networks or information about movies and actors, can be represented as a graph. While you can represent a graph using a relational database, it is going to be hard and cumbersome. If you need to graph data, you can use specialized graph databases that can store information about a graph in a distributed cluster and allow you to implement graph algorithms efficiently.
Column-store Databases
The main difference between column-store databases and other types of databases is how they store data on disk. Relational databases create a file per table and store values for each row sequentially. Columnar databases create a file for each column in your tables.
This structure allows you to aggregate data and to run specific queries more efficiently, but you need to make sure that your data fit the constraints of these databases and they can be used efficiently.
Which one should we pick?
Picking a database is usually an agonizing endeavor, and with so many choices, it may seem like an impossible task. The good news is that you don’t need to pick just one.
Using another modern pattern called “microservices” instead of developing a single monolithic application that implements all features and has access to all data in your system, you can split that application into a set of independent services. Every service solves a narrowly defined task, and it should use only its own database that fits the task of this microservice perfectly.
How are we supposed to learn all of it?
With so many databases around, you may wonder how you are going to learn them all. The good news is that you don’t need to. There are just a few major NoSQL database types, and if you understand how they work, you will be able to learn other NoSQL databases much faster. Also, some NoSQL databases are used more often than others, so it’s better to concentrate your efforts on the most popular solutions.
Here is a list of the most commonly used NoSQL databases that I think you should take a look at:
- MongoDB – This seems to be the most popular NoSQL database on the market. If a company is not using a relational database as its main data store, it is probably using MongoDB. It is a versatile document store with good tooling support. It used to have a bad reputation in its early days because it was losing data in some cases, but it has become more stable and reliable since then. You can take a look at this course about MongoDB if you want to learn more.
- DynamoDB – If you are using Amazon Web Services (AWS), you should learn more about DynamoDB. It’s a rock-solid, scalable database that provides low latency, a rich feature set, and integration with many other AWS services. The best part is that you don’t need to deploy it yourself. In a few clicks, you can set up a scalable DynamoDB cluster capable of processing thousands of requests. If you are interested in it, you can take a look at this course.
- Neo4j – This is the most widespread graph database. It’s a scalable and stable solution that you can use if you want to embrace the graph data model. If you want to know more, you can start with this course.
- Redis – While other databases described here can be used to store the main data of your application, Redis is commonly used to implement a cache and store auxiliary data. In many cases, you may end up using one of the aforementioned databases in tandem with Redis. To learn more, you can take a look at this course.
Get Ready for 2018 with NoSQL
NoSQL databases is a vast and quickly developing field. They allow you to store and process more data than ever before, but it comes at a price.
These databases don’t have the same features that relational databases have and it may be hard to wrap your head around how to use them. However, once you’ve understood this, you will be able to use a scalable and distributed database that can handle a tremendous amount of read and write requests, which will be extremely important as we continue to produce more and more data.

Related Articles

12 REALITIES of Daily Life as a Programmer
What’s the daily life of a programmer like? A programmer’s daily life consists of auditing and debugging code, coding new…

13 POWERFUL Productivity Tips for Developers
Great productivity is one of the best soft skills you can have as a developer. I’ve used these tips to…

Impostor Syndrome as a Programmer
Believing that you’re somewhat unqualified for your job is a problem faced by the best of us. When those thoughts…