 Over the past few months, I taught myself machine learning. I did this without a MOOC (massive open online course), like Coursera or edX, and without a book. I used only the magic of a few YouTube videos, several blog posts, GitHub, and hands-on experimentation.
Over the past few months, I taught myself machine learning. I did this without a MOOC (massive open online course), like Coursera or edX, and without a book. I used only the magic of a few YouTube videos, several blog posts, GitHub, and hands-on experimentation.
It has been a rewarding experience, though in retrospect, some things could have been done better. Here I share some advice for those who choose to take this path, as well as some things they should expect to encounter. I’ll also help you decide whether or not this path is for you.
Indeed, the world of ML (machine learning) is very powerful and complex, but like most computer science fields, there’s always room for beginners.
It’s easy to think of ML as something too complex to teach yourself—after all, it is a type of artificial intelligence. But this is far from the case. It takes a little grit to get through it all, but it is definitely doable. Let’s get to it!
What Exactly Is Machine Learning?
Machine learning can look mystical if you only look at what it has been used to create. Although it is incredibly useful, the underlying concept behind ML is simple.
Machine learning involves training computers to recognize patterns and make meaning from them. We apply many different techniques to do this, but in the end, the magic comes from brute force: the computer simply looks at thousands of data samples and makes small adjustments to its understanding over time. Given enough time, its understanding of the world can become accurate enough to be useful.
ML is all really just math and brute force.
Paralyzed by Choice
The world of ML is not unlike the world of programming. They’re both comparable to a field full of deep burrows. Enter one burrow and you can just keep on going deeper and deeper.
If you want to enter another burrow, you have to leave your current one and start afresh in the new one. Sure, some of the things you’ve learnt in the old burrow could be of use in the new one, but there’s also so much in this new burrow, too!
In “vanilla” programming, these burrows are areas like game development, mobile development, front-end web development, and server-side development. In machine learning, these burrows are ML branches like reinforcement learning, regression, computer vision, unsupervised learning, and more.
If you’re like me, this large amount of choice can be paralyzing because each field has a lot of depth and potential. Learning takes time, and time is precious. How do you choose which one to invest your precious time in?
Of course, it really depends on you. Just like your choice of programming burrow, your choice of ML burrow is personal. Look into them and their applications, and make your choice.
But if you want to play it safe, I suggest choosing an ML field that applies to your current field. For example, reinforcement learning is useful in games, computer vision can be useful in mobile applications and cloud services, and regression is useful for data-centric fields.
Whatever your choice, I advise you not to spend too much time trying to decide what to learn instead of actually learning. If it sounds interesting, try it out. You can always leave your current ML field if you don’t like it—and you would have learned something potentially useful by the time you leave anyway.
There is a definite danger of choice paralysis here. It can be ever-present—even if you’ve chosen a field, you now have to choose what to do inside that field.
Of course, think before you choose, but eventually, just pick something and learn.
The Learning Process
 The process that I used for teaching myself machine learning was actually dead simple. I started with a few YouTube videos (I recommend 3Blue1Brown’s series on neural networks, an important introductory ML concept) to get the underlying concepts down. ML seemed doable and fun, so I looked into the different types of machine learning.
The process that I used for teaching myself machine learning was actually dead simple. I started with a few YouTube videos (I recommend 3Blue1Brown’s series on neural networks, an important introductory ML concept) to get the underlying concepts down. ML seemed doable and fun, so I looked into the different types of machine learning.
After a bit of looking around, reinforcement learning caught my eye. There were a few reasons for this, some of which may also prove helpful to you:
- The uses: As I mentioned before, the applications of an ML field can be a large factor that influences your choice. I’m a game developer, so reinforcement learning definitely looked intriguing and exciting to me.
- The frameworks: In an ideal world, the tools made available to you shouldn’t shape what path of ML you choose. But alas, they do. A lot of the frameworks for other fields of machine learning weren’t attractive to me. I was trying to find a framework that had a relatively large and active community, looked user- and beginner-friendly, and used a language I was comfortable with (this constraint was specific to me, but it’s also not a bad idea to learn another language, too). Look into the frameworks and tools available when making your choice—they’ll be what you’ll be spending several hours with in the future.
After making my choice, I went ahead and learned how to use Unity’s machine learning module through their GitHub documentation and started looking into things I could try and experiment with.
One thing you should know is that many machine learning frameworks have fantastic tutorials. Provided that you have a bit of background information, they can definitely be enough to get your feet off the ground and into some meaningful experiments. If you supplement these tutorials with occasional Google searches for things that you don’t completely understand, you should be perfectly fine.
Some frameworks also have tons of sample code to help you break the ice. Most good frameworks should have these—they’re really helpful and can teach you some interesting things as well.
I used the exact same process to teach myself deep learning for computer vision (training computers to recognize images). The process is effortful and self-driven, but it surely works. However, like any process, it has its drawbacks.
The Three Main Problems
1. The Math
To put it frankly, the math behind ML can be terrifying. Machine learning involves a lot of advanced probability, calculus, and other dark mathematical voodoos. If you don’t have that mathematical knowledge, a lot of the math that appears in blog posts and discussion boards will look like complete gibberish.
This can be very intimidating, because even when you’re looking for an answer to a seemingly simple question, you could find answers with confusing math/mathematical terms. This can be especially confusing for someone who doesn’t have an undergraduate education in probability and calculus.
It’s important to not let this intimidate you. There are two reasons for this:
Firstly, most of this math is completely nonessential. Anything that ML resource writers explain using math can also be explained in plain English, and many of the mathematical explanations they provide are simply there to prove things already mentioned or to be mentioned.
Granted, some websites and posts expect you to understand the math and hence don’t explain it in layman’s terms, but plenty of other resources only treat the math as a supplement. Given that you have the tenacity to look for enough resources and the realization that it’s OK to only glance over the math with only the faintest idea of what’s going on, you should be relatively fine.
Secondly, some of this math looks more complex than it really is, because math has the tendency to look difficult. Let’s look at a trivial example from ML:
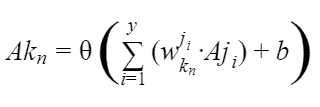
Take a second to look at that formula. You may not fully understand this, but you can see that there’s a summation of products, an addition of another unrelated value, and a function being operated on the resultant output.
Now, let me reveal to you the actual meaning of this equation, step by step:
- In ML, neural networks are data structures that contain layers of nodes. Let’s consider two consecutive layers: layer j and layer k.
- Both of these layers have y number of nodes, and each node is donated by LLPL, where LL stands for the letter of the node’s layer, and PL stands for its position in that layer.
- Each node in layer k is going to want to know the value (denoted by A) of all the nodes in the previous layer, layer j.
- When it is retrieving the value of each node, it is going to multiply it by something called a weight, denoted by w.
- It’s going to add all these products and then add a number called a bias (denoted by b) at the end.
- Then, finally, it will limit the result of this summation to a specified range using a function (denoted byθ()) and store it.
See? It looks hard to grasp, but if you had the right background information, and you saw this somewhere, it would make sense. There are other equations derived from this, and if you understand this one, others will simply make sense too.
As you learn more, your background information will generally increase, and a few more equations will begin to make more sense.
The point is, you should take the time to try and understand some of the math before you outright dismiss it—some of it will be understandable.
2. The Cliff
 ML has what I call a cliff learning curve. The beginning is easy to understand and follow, but once you decide to dig a little deeper, all manner of things suddenly have significance, such as hyperparameters, learning rates, and regularization. All these things must be learned and require their own time to understand and master.
ML has what I call a cliff learning curve. The beginning is easy to understand and follow, but once you decide to dig a little deeper, all manner of things suddenly have significance, such as hyperparameters, learning rates, and regularization. All these things must be learned and require their own time to understand and master.
You may find yourself using some things in ML that you don’t completely understand because you don’t want to invest the time to fully understand them. That is completely fine—sometimes it’s just a bonus to understand certain things.
The cliff isn’t only present in the learning process but in the resources you find over the internet. It’s not uncommon to see a sudden jump in the complexity of the posts you find as you try to learn more and find answers to deeper questions. Honestly, this is can be hard to mitigate, but it’s also not too much of a challenge.
Of course, looking for more posts on websites such as Quora or Medium and using websites like Reddit and Data Science Stack Exchange definitely helps. But you can also benefit from trying to contact other data scientists. Some ML communities use places like Gitter to communicate. Don’t be shy! They can be really helpful.
It should be noted that these jumps usually exist because at some point, the ML community expects for you to have taken a formal class or MOOC on the topic or to have read an ML book. But this post is about learning ML without those, so we’ll have to manage.
3. The Reading
This is only a minor problem, really. One thing about being a self-taught programmer is that you often don’t find yourself having to read much. You might read some detailed documentation or posts every once in a while, but a lot of the learning is from videos, forums, Stack Overflow pages, and quick and short tutorials with self-explanatory code snippets. Hence, a form of reading laziness can develop over time.
ML isn’t like this. ML can require quite a bit of reading and patience—it’s not like other things where you can quickly Google something, get the gist of the information, and simply extrapolate the rest of the way. If you’re like me and are often too lazy to read a lot to understand something, be ready to shake that laziness off. Read.
As a side note, consider reading a few research papers (like the ones on arXiv.org) every once in a while in the ML field you choose. Some interesting things can come up.
The Benefit: Project-Based Learning
Though teaching yourself machine learning can have its challenges, it has two large benefits: freedom to explore (which is almost always fun) and project-based learning.
I truly believe that project-based learning is one of the best ways to learn programming. It gives you a perfect blend of theoretical and street knowledge and allows you to create beautiful things in the process. My method of learning ML somewhat depends on it. Having a project gives you a clear focus on the things you need to learn.
The internet is a deep sea, and if you simply dive in, you can easily get lost, overwhelmed, and confused. If you have a project, it’s immediately easier to filter out so much of the noise because you have a better idea of what you need and what you don’t.
Your project also acts as a source of encouragement. When things go awry, you can just look ahead and picture what you’re trying to do, and you can gain a new breath of energy. And by the time you’ve finished those introductory projects, you will have a good foundation in ML to decide what to do next with it or just to drop it for something else.
This Is Not a Substitute
Before I end, I’d like to mention something rather important: Please don’t use this method alone if you want to learn machine learning seriously.
ML is very different from some other computer science fields. It’ll be very hard to get anywhere significant enough for a professional environment if you don’t read a book and/or take a formal course. This type of self-teaching has some benefits, for sure, but after a certain limit, the benefits it provides are no longer worth the effort it demands.
If you only want to test the waters of ML, or only want to know ML for a specific project, go ahead and use only this method. Otherwise, do this type of self-tutorage in conjunction with a book or MOOC, or use this method alone for a while, and then transition to something heavier.
An Adventure Waiting for You
 Machine learning was indeed an adventure for me, especially because I chose to create my own path. Whatever path you choose, you should try machine learning for yourself.
Machine learning was indeed an adventure for me, especially because I chose to create my own path. Whatever path you choose, you should try machine learning for yourself.
Remember:
- Avoid being paralyzed by the options in ML. You can always choose another field if you find out you don’t like your current one. Consider the applications and available tools in your choosing process.
- Don’t be intimidated by the math. You can do without a lot of it, and some of it looks harder than it really is.
- Get ready for the cliff difficulty curve—but remember that frameworks themselves provide great tutorials and sample code.
- Don’t be afraid of reading.
- Self-teach with projects in mind. Projects are amazing—they give you focus and encouragement.
- If you want to take ML very seriously, eventually read a book on ML, take a MOOC, or both.
There’s a massive amount of potential in machine learning. It has both the breadth and depth to have a place for almost any type of programmer. As developers and creators, we should never stop learning and experimenting. Machine learning is a chance to keep this philosophy alive for you, and you could potentially find something you’ll use for many years to come.

Related Articles

12 REALITIES of Daily Life as a Programmer
What’s the daily life of a programmer like? A programmer’s daily life consists of auditing and debugging code, coding new…

13 POWERFUL Productivity Tips for Developers
Great productivity is one of the best soft skills you can have as a developer. I’ve used these tips to…

Impostor Syndrome as a Programmer
Believing that you’re somewhat unqualified for your job is a problem faced by the best of us. When those thoughts…