Software development is in demand today and will be for at least the next several years. The average compensation is very competitive, and there are very few barriers to entry.
Database programming and development are critical components of software development. Most developers need access to large databases, and SQL is the language for database programming–which explains why SQL is one of the top 10 most popular programming languages today.
If software development, especially SQL development, is such a thriving field with so many opportunities, then why have so many developers not mastered SQL?
The single reason why many developers who write SQL have not mastered it is that they have not mastered the foundational basics.
Because of the increasing demand for software developers, many developers face a common problem, often referred to as “the employer expectation that developers must become experts in everything.” That expectation, combined with the high demand for developers, has created circumstances under which developers must learn an incredible amount of information as quickly as possible. Consequently, if they cannot understand the value of a concept quickly, then they skip it or invest very little time into learning it.
SQL syntax, the actual data, the relational database management systems (RDBMSs), and how to use ancillary third-party tools effectively (i.e., software products from Redgate, ApexSQL, SentryOne, etc.) are all regarded as practical and important skills for SQL developers. Methods for becoming more competent in these areas are already widely discussed in the industry.
The theory, on the other hand, is rarely even mentioned, and it’s rarely considered pragmatic to spend a great deal of time and effort on it.
A personal anecdote of mine highlights why theory is so important to know:
A dog breeder once told me that in the late 1990s, prior to Disney’s release of the animated television series “101 Dalmatians,” experienced dog breeders were typically the only supplier of this type of dog. Following the release of the movie though, demand for Dalmatians skyrocketed, and many people became dog breeders in response.
Unfortunately, both breeders and their customers were caught up in the “hype” of buying and selling Dalmatians without a genuine concern for the process of raising and caring for the dogs. When people are motivated to do something for the wrong reasons (like breeding and raising dogs to make a quick profit), it is often the case that the quality of both the process and the end result suffer significantly. And it’s for this reason that the genetics and behavior of Dalmatians in the U.S. have declined.
Database architects, developers, and administrators may not have much in common with dog breeders, but approaching any of these professions without a methodical, quality-focused mindset will cause serious problems. For SQL, the theory that all developers should know is the relational model. Itzik Ben-Gan and C.J. Date noted that this notion is a critical foundation for SQL, but it’s also a deceptively difficult concept that a significant number of database professionals lack sufficient knowledge of. [1]
At this point, you are probably wondering why insufficient relational model comprehension is an issue and whether or not you need to concern yourself with it.
If you work with SQL, you need to understand the relational model. Considering the importance of performance in all aspects of SQL development, understanding this theory will allow you to take advantage of small performance opportunities and to avoid large and costly problems.
I’m going to walk you through the major components of the relational model. By presenting these theoretical concepts concisely, explaining its practical implications, and providing examples, I think you will find learning it to be well worth the time investment.
Theoretical Foundations of SQL
The theoretical concepts behind programming are important, especially for SQL, since it is the programming language most naturally compatible with mathematics.
The relational model was built on a combination of predicate logic and set theory. Consequently, understanding the relational model requires first understanding the related theories and frameworks in mathematics and logic.
For the purposes of this article, we’re going to limit our discussion of predicate logic and set theory to how it relates to the relational model.
Additionally, all of the concepts relevant to our discussion have been revised multiple times, so I recommend comparing the most recent definition with the originals in order to comprehend their core elements and defend yourself against critics. For example, there is a counter-argument to set theory that appears in almost every in-depth discussion on the subject, called “Russell’s Paradox.” [2]
Predicate Logic
Let’s talk first about predicate logic. Predicate Logic is probably the piece of the relational model that is the most intuitive, at least at a basic level. Steve Kass aptly characterized predicate logic as: “A mathematical framework for representing and manipulating expressions that are true or false: facts or falsehoods.” Some key components to the framework include propositions, predicates, and logical operators. These terms may be defined as follows:
1) A proposition is a true or false statement.
2) A predicate is a proposition that contains one or more variables (e.g., the expression a < 5 is a predicate that contains the proposition a)
3) The four most basic logical operators, negation (~), conjunction (∧), disjunction(∨), and the conditional(⊃ or →) are used to combine propositions.
The parallel to SQL, here, exists in the control flow elements of the language. Control flow logic in SQL, however, is not the part of the relational model that is more difficult to grasp. As we will see later, most of the confusion is related to set theory. [3]
Set Theory

Perhaps you think predicate logic comes naturally to you. You’ve probably heard the term “set” so often throughout your SQL development career that you probably think that you already know what it means. For example, queries return “Result Sets,” not “A List of Records” (at least, not when SQL is used relationally).
If these assumptions describe your current thoughts, then brace yourself, because it’s not as easy as you think.
There are two reasons why set theory is more difficult. Unlike predicate logic, it is more difficult to translate set theory problems into English. If you disagree, then count the number of control-flow errors that you have had to troubleshoot and compare those with the number of errors with queries. It may also be the case that we naturally think in terms of individual objects rather than in groups. Whatever the reasons may be, I would humbly suggest that you approach set theory more methodically.
Set theory is: “…the mathematical theory of well-determined collections, called sets, of objects that are called members, or elements, of the set.” The concepts “membership” and “relation” are foundational elements of set theory. A relation is the mathematical representation of a set, and membership describes the relationship of the set’s elements.
Sets are members of other sets, have no order, and do not allow nulls. Set membership is denoted as x ∋ y, which translates to “x is a member of y.”
One of the sets, referred to as “the empty set,” is a set without members. (Since there is only one way to represent the empty set mathematically, it is more correct to use the article “the” than “a” when referring to it.)
Notice that the empty set demonstrates the use of predicates in set theory, which is important when we are dealing with infinite sets or sets too large to list all of their values. [4] The rest of set theory will make more sense as it is explained through the context of the relational model.
In contrast to other programming languages, set theory is easier to apply to SQL because its result sets may be described without their corresponding execution plans; in other words, the declarative nature of the language is more conducive to the application of mathematical theory than an imperative language.
The Relational Model
Defining the relational model requires defining data model, which “is an abstract self-contained, logical definition of the data structures, data operators, and so forth, that together make up the abstract machine with which users interact.” [5] The relational model was originally defined in 1969 by Edgar F. Codd in his research report, “Derivability, Redundancy, and Consistency of Relations Stored in Large Data Banks.” Since I have found his revision, “A Relational Model of Data for Large Shared Data Banks,” to be very helpful, I will cite two sentences that summarize the majority of the report.
We can define the relational model as: “A model based on n-ary relations, a normal form for data base relations, and the concept of a universal data sublanguage…certain operations on relations (other than logical inference) are discussed and applied to the problems of redundancy and consistency in the user’s model.” [6]
There is a lot to unpack here. C.J. Date discussed the concept of n-ary relations, in “SQL and Relational Theory,” to clarify the common misconception that databases which conform to the relational model are not limited to two dimensions.
The introduction of the “normal form” concept is one that you are probably very familiar with (though, not in the formal sense). Codd introduced several normal forms beyond the standard 1-NF, 2-NF, and 3-NF (i.e., the first, second, and third normal forms, respectively), but for our purposes, just be aware that they are a critical part of the relational model. Itzik Ben-Gan’s definition of normalization is sufficient for our purposes: “Normalization is a formal mathematical process to guarantee that each entity will be represented by a single relation.”[7]
The last sentence contains more direct references to SQL and two categories of problems the relational model was designed to solve. By “the concept of a universal data sublanguage,” Codd is referring to SQL, of course. The expression “operations on relations” refers to what we call set operators (Union, Intersect, Intercept, etc.) today. From a purely pragmatic perspective, the implications of the phrase, “the problems of redundancy and consistency,” are quite important; dealing with nulls and duplicate problems has roots back to the very definition of the relational model.
Even before you fully understand the relational model, you can still benefit from the ideas related to duplicates and nulls. In theory, it means avoid them at all costs; otherwise, you are not dealing with sets and therefore, cannot guarantee anything mathematically. In practice, this avoidance may not always be possible, which we’ll discuss a bit more later.
Let’s discuss how you can apply the relational model to become a better SQL developer.
Practical Applications for the Relational Model

Three-Valued logic, referential integrity, set theory, and the deliberate separation between the physical and logical models are often confusing and deserve more attention. These topics are also some of the most common areas in which the relational model is misused or misunderstood, which makes them a great opportunity to demonstrate to you what the practical benefits of understanding the relational model are.
Three-Valued logic is a kind of modified predicate logic with the addition of the “Unknown” truth value. Codd introduced Three-Valued logic to the relational model intentionally because he thought it was a necessary violation; it is one key point on which C.J. Date and Codd disagree.
From a pragmatic perspective, how should you decide how to handle nulls? It depends on a lot of factors. Reporting functions (e.g., “GROUPING SETS” in T-SQL) may use nulls as a kind of aggregate marker, but nulls can also indicate a variety of errors.
Make sure that you always use COALESCE and specify a condition for the “ELSE” clause in “CASE” statements to avoid confusing nulls that signify errors with the kind of expected nulls from aggregates. In other words, plan to address nulls wherever they appear so that you can tell exactly what they mean. Again, C.J. Date’s excellent book, “SQL and Relational Theory,” discusses this concept in more detail and offers more suggestions.
However, it is important for me to distinguish between the term “performance” in the relational model and performance as it relates to the physical model. All of the authors that I’ve mentioned describe the importance to clarify this point, but why?
The physical model, or physical implementation and associated objects (e.g., indexes) are not part of the data model. While it is important for SQL developers to understand how indexes work, the physical management of memory and all aspects of the physical implementation of a database that employers find valuable are not applicable to the relational model.
In essence, if you optimize the logical model as a database architect and SQL developer (i.e., database developer and programmer), then you can minimize the need for your Database Administrator to tune the physical model for performance.
There is a high-performance cost to implementing the relational model, which is why it is not commonly used in data warehouses or data marts. In Online Transactional Processing (OLTP) environments, however, referential integrity is more important than performance, and this value should be reflected in the logical model by utilizing the relational model. So, write SQL queries relationally in any environment whenever possible, but keep in mind that the database design is more limited in database warehouses because performance is a higher priority than referential integrity and even normalization.
Referential integrity is one of the main strengths of a database that conforms to the relational model, but there are also small performance benefits. Referring back to the “no duplicates” requirement, the general idea is that duplicated data does not accurately represent reality. If your goal is to use mathematical theories to represent reality as accurately as possible in your database design, then you won’t have to worry about encountering as many problems in development later on. In fact, this idea applies as much to the earlier discussion about nulls as it does to duplicates.
For example, can you picture how much faster queries would run if you were able to dramatically reduce the number of times you had to specify “DISTINCT”? While completely eliminating duplicates is (in many cases) not practical, you can at least define a primary key on every table to ensure uniqueness. Similarly to the duplicate issue, you may opt for another relational solution by specifying “NOT NULL” on all columns in all tables. By reducing the number of nulls, you are greatly simplifying the work performed by the optimizer.
Set-Based Thinking
If you know an object-oriented programming language, then you are probably quite familiar with loops. I am going to go out on a limb and guess that you could write loops in your sleep – even nested loops might be a piece of cake.
When I learned Visual Basic for Applications (VBA), I picked up the For-Each loop concept quickly; for whatever reason, it was easy to learn the syntax. If you want to do something to all of the records in a column, then just find the first record, the last record, set an interval for incrementing, and boom – you’re done.
Like VBA, many developers probably think SQL is easy to pick up. While these developers think of SQL as an “easy” language to learn, few realize why it is also a difficult one to master.
Explaining the former is fairly simple: it was designed to resemble the English language closely. As I mentioned earlier, it is declarative, rather than imperative [8]. For example, the sentence, “Get the email addresses of all of the prospective customers who looked at my website today” could represent the following query:
For this example, let “ProspectEmail” represent the email address a user entered by creating an account for the website. If this database existed as a series of pieces of paper in folders and file cabinets, then the statement could represent a person physically opening a drawer, finding the folder labeled “LoginInformation,” and flipping through the entries in the front of the folder (where we can assume the most recent files are placed).
The example should demonstrate that the order in which Select statements are written (i.e., their syntax) closely represents the order in which we structure sentences in English.
If resemblance to English is one main reason why SQL is a relatively easy programming language to learn, then how come it is so difficult to “master”?
Remember my casual explanation about how For-Each loops work? I left out one detail: in order for loops to function correctly, the order in which the records are referenced in the table matters.
The DISTINCT operator requires the optimizer to sort the records. Loops, like DISTINCT, violate the definition of a set by requiring the optimizer to sort records. Unlike our previous discussion with DISTINCT, in which its use could be minimized by enforcing uniqueness at the table definition level through referential integrity enforcement via primary keys, there is no similar solution for loops.
Before getting into the solution, it’s worth exploring how and why developers fall into the trap of over-using loops.
The relational model requires an understanding of set theory and predicate logic. Whenever you come up with a loop as the answer to your problem (in a SQL context), it usually means you are thinking about the individual records in your query. From that perspective, it’s quite natural to loop through all of the records in a column, one row at a time.
Unfortunately, as you start to work with larger data sets, you quickly realize why this is not a scalable approach, and that you need to find a better alternative because the performance hit will be increasingly painful.
To borrow a phrase from Itzik Ben-Gan, “set-based thinking” is the characteristic that ultimately determines whether or not you understand the theoretical basis of SQL (i.e., the relational model and especially set theory). Thinking in terms of sets means that you write SQL by visualizing the entire collection (or set) of data that you want to work with and write SQL with that entire set in mind.
Generally speaking, if you are using loops, then it means that you are thinking about the individual objects within the set and attempting to write SQL at the record-level. This view (no pun intended) is simply not what SQL was designed for.
In order to demonstrate what I mean with a clearer example, let’s talk about Tally Tables and how you can use them effectively once you have achieved some level of set-based thinking.
The Power of Tally Tables
Let’s go back to my original hypothetical example of ProspectEmails in the LoginInformation table. Picture a person physically taking records out of storage and associate that image to how the optimizer would handle a loop.

Now visualize your entire data set; it’s a list of prospect email addresses that you want to update because all of these prospects belong to a company that is changing its name, which needs to be reflected in the email address.
Instead of thinking about manually modifying each record in the table, think about the records as a single set. First, create what is called a tally table, which is simply a table of numbers. Then replace the cursor with a select statement, pass a parameter through it, and include a where clause that replaces your counter variable. This article goes into significant detail on different ways of creating and using tally tables.
One helpful way to visualize the difference between a cursor or loop solution from a tally table solution is to think about what the optimizer does at a general level.
Visual representation of DML statements (inserts, updates, selects, etc.)
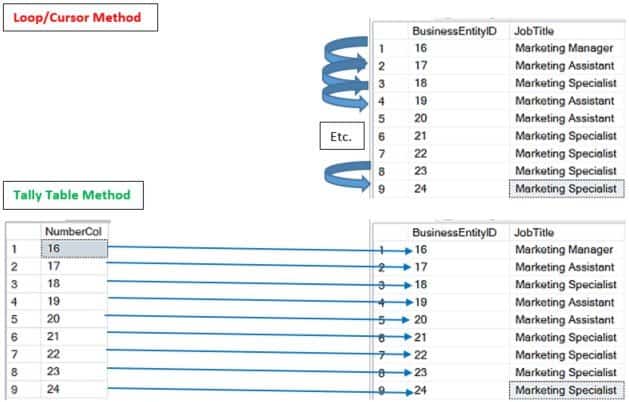
For this image, I used the AdventureWorks2014 sample database in Microsoft SQL Server 2014 Express Edition, and wrote a query that selects all of the job titles that contain “marketing” with their corresponding BusinessEntityID’s. To clarify a point about the image: the arrows in the “Tally Table Method” part do not indicate that the optimizer reads all of these records simultaneously. It thinks of the BusinessEntityID’s as a set or collection, instead of individual objects to iterate through.
There is a limit to what the optimizer can do to optimize a loop or cursor solution because it ultimately has to iterate through all of the code based on the number of iterations and positioning that you specified.
In one great article on SQL Server Central, Jeff Moden explains why tally tables are superior, especially in terms of performance:
The Tally table method wins for Duration, CPU time, and RowCounts. [It] loses in Reads and that bothers some folks, but it shouldn’t. Part of the reason the Tally table method works so well is because parts of the Tally table get cached and those are “Logical Reads” from memory. If you think these differences are small, multiply them by 10,000 or a million and see how much difference there is. If you want performance, stop using loops and start using a Tally table.
Thus, the positive impact of relationally-compliant SQL on the logical processing enables the optimizer to improve the physical processing, as is the case with any tally table solution over a cursor solution.
Conclusion
The complexities of the SQL’s theoretical basis, especially within the relational model and set theory, can seem particularly difficult to learn without any clear benefit. By walking through the relational model in detail, and talking about how predicate logic and set theory support the concept, you better understand this critical foundation of SQL.
The broader lesson, though, is that it is counterproductive to sacrifice the quality of our education in pursuit of staying on top of technology trends. There are significant industry pressures that make it appealing to cut corners and learn only what you need to know.
When it comes to learning theory, however, I think it would be wise to reconsider your time investment decisions with respect to your technological education. Once you consider the longer-term implications of it, understanding the theory behind the practice will provide a greater benefit than cost – particularly for SQL developers.
Footnotes
[1] I very deliberately chose to describe the relational model as “foundational” and “deceptively difficult” because it is both the most widely used model for databases and perhaps the most misunderstood database concept. See C.J. Date’s “SQL and Relational Theory” for more details – especially Appendix F.
[2] Akihiro Kanamori. “Logic and Paradox.” Set Theory From Cantor to Cohen. Department of Mathematics, Boston University. 16-18, Print.
[3] Ben-Gan, Itzik. “Set Theory and Predicate Logic.” Inside Microsoft SQL Server 2008: T-SQL Querying. Ed. Steve Kass, Ed. Ken Jones, Ed. Sally Stickney. United States of America, 2014. 65-68, Print.
[4] Ben-Gan, Itzik. “Set Theory and Predicate Logic.” Inside Microsoft SQL Server 2008: T-SQL Querying. Ed. Steve Kass, Ed. Ken Jones, Ed. Sally Stickney. United States of America, 2014. 44, Print.
[5] Date, C.J. “Setting the Scene.” SQL and Relational Theory: How to Write Accurate SQL Code. California, United States of America, 2015. 15, Print.
[6] Codd, Edgar F. A Relational Model of Data for Large Shared Data Banks. Ed. P. Baxendale. I.B.M. Research Laboratory, San Jose, California, 1970. 1, Web.
[7] Ben-Gan, Itzik. “Background to T-SQL Querying and Programming.” Microsoft SQL Server 2012 T-SQL Fundamentals. Ed. Kristen Borg, Ed. Russell Jones, Ed. Kathy Krause. United States of America, 2012. 7-8, Print.
[8] Ben-Gan, Itzik. “Background to T-SQL Querying and Programming.” Microsoft SQL Server 2012 T-SQL Fundamentals. Ed. Kristen Borg, Ed. Russell Jones, Ed. Kathy Krause. United States of America, 2012. 2, Print.
Good Code Isn’t What Gets You Paid
The developers landing the senior roles and the consulting offers aren’t better engineers than you. They’re known. RDU is John’s coaching program for developers who are done being the best-kept secret on the team.
Book Your Free Call →
Related Articles

12 REALITIES of Daily Life as a Programmer
What’s the daily life of a programmer like? A programmer’s daily life consists of auditing and debugging code, coding new…

13 POWERFUL Productivity Tips for Developers
Great productivity is one of the best soft skills you can have as a developer. I’ve used these tips to…

Impostor Syndrome as a Programmer
Believing that you’re somewhat unqualified for your job is a problem faced by the best of us. When those thoughts…