As software developers, we get to improve by learning many good practices which we strive to apply in our code.\n\nFor instance, we learn the importance of good naming of variables and functions, encapsulation, class cohesion, the usage of polymorphism, concision, readability, code clarity, expressiveness, and many other principles.\n\nIf you consistently deploy all of these practices, you’re in fact doing one thing: respecting levels of abstraction. As we’ll see in greater detail in this article, an abstraction is characterized by what a particular piece of code intends to do as opposed to how it is implemented.\n\nThis is the one principle to rule them all because it automatically applies all the best practices mentioned above and more besides. When you follow it, you’ll find yourself naturally writing code with a high-quality design.\n\nA good design of code pays off in the long run because well-designed and expressive code is manageable. It is vital for long-term projects, and for projects with a team of several developers as well as for big-sized industrial ones.\n\nThis overarching principle is based on simple notions, but it took me years of practice and study to realize how this is the most central notion of all.\n\nTo prove this principle’s key importance, I will define levels of abstraction, show how a lot of best practices of code are equivalent to respecting them, and finally derive a technique for improving the expressiveness of a given piece of code.\n\n
The What and the How
\n\nWhat are “levels of abstraction” in the first place ? This notion is easy to grasp when you look at a call stack. Let’s take the example of a piece of software dealing with financial products. The user has a portfolio of assets that he wants to evaluate; the value of a portfolio is the sum of the values of all the assets it contains.\n\n \n\nThis call stack can be read from the bottom up in the following way:\n\n
\n\nThis call stack can be read from the bottom up in the following way:\n\n
- \n
- To evaluate a portfolio, every asset has to be evaluated.
- To evaluate a particular asset, say that some type of probability has to be computed.
- To compute a probability, there is a model that does mathematical operations like +, -, etc.
- And these elementary mathematical operations are ultimately binary operations sent to the CPU’s arithmetic and logic unit.
\n
\n
\n
\n
\n\nIt is natural to think that the code at the top of this stack is low-level code, and the code towards the bottom is high-level code. But level of what? They are levels of abstraction.\n\nRespecting levels of abstraction means that all the code in a given piece of code (a given function, an interface, an object, or an implementation) is at the same abstraction level. Said differently, abstraction levels are respected if, at a given level, there isn’t any code coming from another level of abstraction.\n\nA given level of abstraction is characterized by what is done in it. For example, at the bottom level of the stack, a portfolio is evaluated. On the next level, assets are evaluated, and so on.\n\nWhen we move from a higher level of abstraction to a lower one, the execution of the tasks in the less abstract level is how we implement the more abstract level. In our example, evaluating an asset is accomplished by computing a probability. We compute a probability (higher abstraction) with elementary mathematical operations (lower abstraction), and so on.\n\n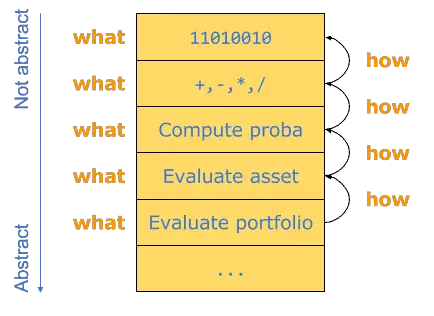 \n\nSo the crucial question to constantly ask yourself when you design or write code is: “In terms of what am I coding here ?”\n\n
\n\nSo the crucial question to constantly ask yourself when you design or write code is: “In terms of what am I coding here ?”\n\n
One principle to rule them all
\n\nI deem respecting the levels of abstraction to be the most important principle in programming, because it automatically implies many other best practices, like keeping it simple (KISS). Let’s see how several well-known best practices are just various forms of respecting levels of abstractions.\n\n
Polymorphism
\n\nMaybe the first thing you thought of when reading about abstraction is polymorphism. Indeed, polymorphism involves providing interfaces or abstract classes to manipulate decoupled implementations of a single concept.\n\nPolymorphism consists of segregating levels of abstraction.\n\nIndeed, for a given interface (or abstract class) and concrete implementation, the base class is abstract and the implementation is less abstract, because the base class describes what it does as an interface, while the implementation code describes how it does it.\n\nNote that the derived class is still somewhat abstract since it is not expressed in terms of 0 and 1, but it is at an inferior level of abstraction compared to the base class. The base class represents what the interface offers, and the derived class represents how it is implemented:\n\n \n\n
\n\n
Good naming, encapsulation, cohesion
\n\nLet’s take the example of a class in charge of maintaining a caching of values. This class lets you add or retrieve values of type V with keys of type K.\n\nIt is implemented with a map<K,V>:\n\n \n\nImagine now that we want the interface to be able to provide the whole set of results at once. Then we add a method to the interface. How do we name this method ? A first try may be “getMap” because it effectively provides the map that associates all the keys to the values in the cache.\n\nBut as you might notice, “getMap” is not a good name. It isn’t a good name because — at the abstraction level of the caching interface — “Map” is a term of how (observe that it appears in the bottom part of the diagram), and not what, so “Map” is not at the same abstraction level as the thing it names. Calling it “getMap” would mix several abstraction levels together.\n\nA simple fix would be to call it “getAllValues” for instance. “Values” is a consistent term with the level of abstraction of the caching interface and is therefore a name that is more adaptable than “Map”.\n\nYou can accomplish good naming by giving names that are consistent with the abstraction level they are used in. This works for variable names, too. Because naming defines levels of abstraction and is therefore such an important topic, we will have a dedicated post about it at a later stage.\n\nBut isn’t it a violation of encapsulation to provide the map of results to the outside of the class in the first place? Indeed, encapsulation is the restriction of access to implementation data inside an object.\n\nActually, the answer depends on whether the very concept of a results container is logically part of the abstraction of the class. If this concept of container is seen as implementation, details then exposing it breaks encapsulation. And if in your design the caching has the responsibility of providing all results at the same time, exposing the concept of container (potentially with read-only attributes) does not break encapsulation.\n\nTherefore, breaking encapsulation means providing information that goes beyond the abstraction level of the interface.\n\nNow imagine that we added a new method in the caching class to do some formatting on values:\n\n\n\nThis is obviously a bad idea because this class is about caching values, not about formatting them.\n\nDoing this would break the cohesion of the class. In terms of abstraction, even though caching and formatting don’t have a what-how relationship, they are two different abstractions because they are in terms of different things.\n\nSo cohesion consists of having only one abstraction at a given place.\n\n
\n\nImagine now that we want the interface to be able to provide the whole set of results at once. Then we add a method to the interface. How do we name this method ? A first try may be “getMap” because it effectively provides the map that associates all the keys to the values in the cache.\n\nBut as you might notice, “getMap” is not a good name. It isn’t a good name because — at the abstraction level of the caching interface — “Map” is a term of how (observe that it appears in the bottom part of the diagram), and not what, so “Map” is not at the same abstraction level as the thing it names. Calling it “getMap” would mix several abstraction levels together.\n\nA simple fix would be to call it “getAllValues” for instance. “Values” is a consistent term with the level of abstraction of the caching interface and is therefore a name that is more adaptable than “Map”.\n\nYou can accomplish good naming by giving names that are consistent with the abstraction level they are used in. This works for variable names, too. Because naming defines levels of abstraction and is therefore such an important topic, we will have a dedicated post about it at a later stage.\n\nBut isn’t it a violation of encapsulation to provide the map of results to the outside of the class in the first place? Indeed, encapsulation is the restriction of access to implementation data inside an object.\n\nActually, the answer depends on whether the very concept of a results container is logically part of the abstraction of the class. If this concept of container is seen as implementation, details then exposing it breaks encapsulation. And if in your design the caching has the responsibility of providing all results at the same time, exposing the concept of container (potentially with read-only attributes) does not break encapsulation.\n\nTherefore, breaking encapsulation means providing information that goes beyond the abstraction level of the interface.\n\nNow imagine that we added a new method in the caching class to do some formatting on values:\n\n\n\nThis is obviously a bad idea because this class is about caching values, not about formatting them.\n\nDoing this would break the cohesion of the class. In terms of abstraction, even though caching and formatting don’t have a what-how relationship, they are two different abstractions because they are in terms of different things.\n\nSo cohesion consists of having only one abstraction at a given place.\n\n
Concision, readability, expressiveness
\n\nLet’s go down to the function (or method) level.\n\nTo continue on the financial example, let’s consider financial indices such as the Dow Jones or the S&P that contain a collection of equities like Apple, Boeing, or Caterpillar.\n\nSay that we want to write a function that triggers saving an index in a database after having done some checks on it. Specifically, we want to save an index only if it is valid, which means, say, having an ID, being quoted on a market, and being liquid.\n\nA first try for the function implementation could be the following:\n\n\n\nWe could object to this implementation on the grounds that it has a complex Boolean condition that could be grouped and taken out of the function for code concision and readability:\n\n\n\nWhen we think about this fix, it is in fact pushing out the implementation of how an index is considered valid (having an ID, quoted, liquid) and replacing it with what the save depends on (being valid), which is consistent with the level of abstraction of the save function.\n\nAn interesting thing to note at this point is that respecting levels of abstraction goes beyond the simple concision of code. Indeed, we would still have done this fix even if being valid only meant having an ID.\n\nThis wouldn’t have reduced the number of characters typed in the code (it would even have slightly increased it), but this would have improved code clarity by respecting levels of abstraction.\n\nLast but not least, there’s expressiveness, which is the focus of my site Fluent C++.\n\nSay that we want to remove some components from the index if they are not valid.\n\nA first trial might write a for-loop to do this, but the best solution here in C++ is to use the remove_if algorithm of the C++ Standard Template Library (STL). STL algorithms say what they do, as opposed to hand-made for-loops that show how they are implemented. By doing this, STL algorithms are a way to raise the level of abstraction of the code to match the one of your calling site.\n\nI think expressiveness is the primary characteristic to strive for in code. This is particularly true for long-term or industrial-strength projects because expressive code is manageable in that it tells what it means to do.\n\nIn expressive code, bugs can be spotted and fixed, new features can be added, and performance can be tuned. By using expressive code, new developers in a project can come up to speed fairly quickly, move forward at a fast pace, and draw satisfaction out of their efforts.\n\n
Transforming obscure code to expressive code: Raising levels of abstraction
\n\n \n\nUnfortunately, all the code out there is not expressive. For instance, you might have legacy code in your system (as many companies do), which is obscure and wastes developers’ energy and motivation.\n\nA technique can be derived from respecting the levels of abstraction that allows you to transform an obscure piece of code into an elegant and expressive one.\n\nIn many cases of obscure code, lower-level code is in the middle of a higher-level layer of the stack — levels of abstraction have been disrespected.\n\nThe problem is code that describes how it performs an action rather than what action it performs. To improve such a piece of code, you need to raise its level of abstraction.\n\nAnd to do so you can apply the following technique:\n\nIdentify what things the code does, and put a label on each one of them.\n\nThis has the effect of dramatically improving the expressiveness of the code. Let’s illustrate with an example. The following case is written in C++, but the technique is not specific to a language, which is what makes it so powerful.\n\nLet’s consider an application where the user can plan a trip across several cities in the country. He would drive straight through from one city to the next if they are close enough (under 100 kilometers, say); otherwise, he would take a break on the road between two cities. The user doesn’t take more than one break between two cities.\n\nWe have the planned route in the form of a collection of cities.\n\nYou need to write a piece of code that works out how many breaks the driver has to take in order to budget his time effectively.\n\nThe existing class, City, represents a city on the route. It can provide its geographical attributes, amongst which are its location, which is represented by a class, Location. And a Location can itself compute the driving distance to any other location on the map:\n\n\n\nHere is a possible implementation of a function to determine how many breaks the driver has to take:\n\n\n\nThis code hasn’t been taken from one codebase in particular, but I have synthesized different techniques I’ve seen in production code or from being advised on the Internet in order to make a realistic example.\n\nThe problem with this code is that it doesn’t say what it intends to do; rather, it invites the reader to work out what is happening in it—this code is not expressive. Let’s use the previous guideline to improve expressiveness: that is to say, let’s identify what things the code does, and replace each one with a label.\n\nLet’s start with the iteration logic:\n\n\n\nMaybe you have seen this technique applied before. This is a trick to manipulate adjacent elements in a collection. it1 starts at the beginning, and it2 points to the element right before it1 all along the traversal. To initialize it2 with something, we start by setting it at the end of the collection and check that it2 is no longer at the end within the body of the loop to actually start the work.\n\nNeedless to say, this code is not exactly expressive. But now we have determined what it means to do: it aims to manipulate consecutive elements together.\n\nLet’s tackle the next piece of the code, in the condition:\n\n\n\nTaken on its own, it’s easier to understand what the code means to do. It determines whether two cities are farther away than MaxDistance.\n\nLet’s finish the analysis with the variable nbBreaks:\n\n\n\nHere, the code increments the variable depending on a condition. It means to count the number of times a condition is satisfied.\n\nIn summary, function:\n\n
\n\nUnfortunately, all the code out there is not expressive. For instance, you might have legacy code in your system (as many companies do), which is obscure and wastes developers’ energy and motivation.\n\nA technique can be derived from respecting the levels of abstraction that allows you to transform an obscure piece of code into an elegant and expressive one.\n\nIn many cases of obscure code, lower-level code is in the middle of a higher-level layer of the stack — levels of abstraction have been disrespected.\n\nThe problem is code that describes how it performs an action rather than what action it performs. To improve such a piece of code, you need to raise its level of abstraction.\n\nAnd to do so you can apply the following technique:\n\nIdentify what things the code does, and put a label on each one of them.\n\nThis has the effect of dramatically improving the expressiveness of the code. Let’s illustrate with an example. The following case is written in C++, but the technique is not specific to a language, which is what makes it so powerful.\n\nLet’s consider an application where the user can plan a trip across several cities in the country. He would drive straight through from one city to the next if they are close enough (under 100 kilometers, say); otherwise, he would take a break on the road between two cities. The user doesn’t take more than one break between two cities.\n\nWe have the planned route in the form of a collection of cities.\n\nYou need to write a piece of code that works out how many breaks the driver has to take in order to budget his time effectively.\n\nThe existing class, City, represents a city on the route. It can provide its geographical attributes, amongst which are its location, which is represented by a class, Location. And a Location can itself compute the driving distance to any other location on the map:\n\n\n\nHere is a possible implementation of a function to determine how many breaks the driver has to take:\n\n\n\nThis code hasn’t been taken from one codebase in particular, but I have synthesized different techniques I’ve seen in production code or from being advised on the Internet in order to make a realistic example.\n\nThe problem with this code is that it doesn’t say what it intends to do; rather, it invites the reader to work out what is happening in it—this code is not expressive. Let’s use the previous guideline to improve expressiveness: that is to say, let’s identify what things the code does, and replace each one with a label.\n\nLet’s start with the iteration logic:\n\n\n\nMaybe you have seen this technique applied before. This is a trick to manipulate adjacent elements in a collection. it1 starts at the beginning, and it2 points to the element right before it1 all along the traversal. To initialize it2 with something, we start by setting it at the end of the collection and check that it2 is no longer at the end within the body of the loop to actually start the work.\n\nNeedless to say, this code is not exactly expressive. But now we have determined what it means to do: it aims to manipulate consecutive elements together.\n\nLet’s tackle the next piece of the code, in the condition:\n\n\n\nTaken on its own, it’s easier to understand what the code means to do. It determines whether two cities are farther away than MaxDistance.\n\nLet’s finish the analysis with the variable nbBreaks:\n\n\n\nHere, the code increments the variable depending on a condition. It means to count the number of times a condition is satisfied.\n\nIn summary, function:\n\n
- \n
- Manipulates consecutive elements together.
- Determines if cities are farther away than MaxDistance.
- Counts the number of times a condition is satisfied.
\n
\n
\n
\n\nOnce this analysis is done, we are really close to turning this obscure code into a meaningful one.\n\nThe guideline was to put a label over each of the three things the code does, in order to hide the implementation code. Here, we are going to do the following:\n\n
- \n
- For manipulating consecutive elements, we can create a component that we would call “consecutive,” and that would transform a collection of elements into a collection of element pairs, each pair having an element of the initial collection and the one next to it. For instance, if route contains {A, B, C, D, E}, consecutive (routes) would contain {(A,B), (B,C), (C, D), (D, E)}. In C++ this is called a range adaptor. You can see my implementation here. One such adaptor that creates a pair of adjacent elements has recently been added to the popular range-v3 library under the name of sliding.
- For determining whether two consecutive cities are farther away from each other than MaxDistance, we can simply use a function object that we would call FartherThan. I recognize that C++11 functors have mostly been replaced by lambdas, but this functor here has the slight advantage over a named lambda because it can completely hide the implementation code from the computeNumberOfBreaks function. This can also be achieved with a lambda, but it involves a bit more work (as shown in this post about making code expressive with lambdas). So here let’s just stick with a functor to get the point across:
\n
\n
\n\n\n\n
- \n
- For counting the number of times a condition is satisfied, we can just use the STL algorithm, count_if.
\n
\n\nHere is the final result, obtained by replacing the code with the corresponding labels:\n\n\n\n(Note: the native count_if C++ function takes two iterators to a begin and end of a collection. The one used here simply calls the native one, with the begin and end of the passed range.)\n\nThis code shows what it does and is much more expressive than the initial one. The initial one only told how it did the work, leaving its reader to do the rest of the job.\n\nThe above technique can be applied to many unclear pieces of code to turn them into very expressive ones. So next time you stumble upon obscure code that you want to refactor, think about identifying what things the code does and replacing each one with a label.\n\nYou’ll be surprised with the results.\n\nLabeling focuses on the code itself, though. If you want to learn an interesting methodology to writing clean code, you should definitely check out John’s post about how to write clean code.\n\n
Code for the Long Term
\n\n \n\nFollowing the principle of respecting the levels of abstraction will help you make good choices when designing code. This leads to greater expressiveness and robustness in your code, making it an asset for the future of your codeline and your company, rather than a liability.\n\nIf you think about this principle when designing your code and constantly ask yourself the question, “In terms of what am I coding here?”, your code will flow naturally, perform its function well, and be a pleasure to use for the other programmers and developers who have to work with it.\n\nAs developers, expressive code is generally what we call “beautiful” code. And having code that developers find beautiful is something a software company should look for. By identifying what things the code does and replacing each one with a label, we know how to raise levels of abstraction in order to make code more expressive.\n\nAs I indicated throughout the post, many best practices depend on respecting levels of abstraction.
\n\nFollowing the principle of respecting the levels of abstraction will help you make good choices when designing code. This leads to greater expressiveness and robustness in your code, making it an asset for the future of your codeline and your company, rather than a liability.\n\nIf you think about this principle when designing your code and constantly ask yourself the question, “In terms of what am I coding here?”, your code will flow naturally, perform its function well, and be a pleasure to use for the other programmers and developers who have to work with it.\n\nAs developers, expressive code is generally what we call “beautiful” code. And having code that developers find beautiful is something a software company should look for. By identifying what things the code does and replacing each one with a label, we know how to raise levels of abstraction in order to make code more expressive.\n\nAs I indicated throughout the post, many best practices depend on respecting levels of abstraction.

Related Articles

11 Tips to Be a Better Software Engineer
1. Get a Programming Mentor If you want to accelerate your programming career, there’s few things more effective than having…

Why You Should Think Like a Computer Scientist and Not a Programmer
According to the United States Bureau of Labor Statistics, there were 8.6 million science, technology, engineering, and math (STEM) jobs…

Protect Your Passwords
Recently, I created an account with a site (which shall remain nameless). Everything seemed cool at first. Then I submitted…