 There’s so much to keep track of when it comes to meta tags, HTML, and SEO. Some tags can affect the website’s search results and how high it appears in the results list.
There’s so much to keep track of when it comes to meta tags, HTML, and SEO. Some tags can affect the website’s search results and how high it appears in the results list.
Knowing and understanding the types of tags programmers need to boost search engine optimization is one of the essential ways to provide helpful data about the page to search engines and users.
In this post, I’ll offer you all you need to know about HTML and meta tags, so you can be sure the pages you design are optimized for search engines. This improves the quality of your work and, as a result, your status as a professional developer.
What Are Meta Tags?
Right away, programmers might have some confusion about what exactly a meta tag is and what it does. Meta tags are short strings of text describing a web page, but they don’t ordinarily appear on the page itself, even though they affect how it appears in search results. Instead, programmers can see meta tags in the page’s source code.
Each tag is essentially a small content descriptor that tells search engines the main point of a page. Sometimes, the coder will see tags on certain websites, like blogs or social media websites, but these tags and meta tags aren’t the same. Tags that a user can see usually assist with the navigation of a website, but meta tags help search engines crawl the content.
When it comes to tagging, meta means “metadata.” They only exist within the HTML, usually in the <head> element of a page, and they remain invisible to the user. Meta tags provide search engines with data about the information on a website.
HTML also uses different types of tags in addition to meta tags, which might be a bit confusing. Basically, meta tags only affect search engines, and regular HTML tags, like <body>, <p>, or <img>, affect what the user sees on the page. Web designers will also use CSS, Bootstrap, Javascript, or another language to alter how content looks or performs on a page.
How Should Programmers Use Meta Tags?
Now that you know what a meta tag is, how should you use them? Let’s start with the basics. Particular HTML SEO tags affect the website’s rankings, but not all of them do. Professional programmers ought to understand which tags affect rankings.
Meta Tags
Meta tags describe all tags relating to metadata, and each one must use the <meta> tag. Programmers can include different attributes inside the tag, which tells browsers and search engines different information about the web page to help the website stand out in search results. That information can be about a character set, various meta keywords, author, description, and more.
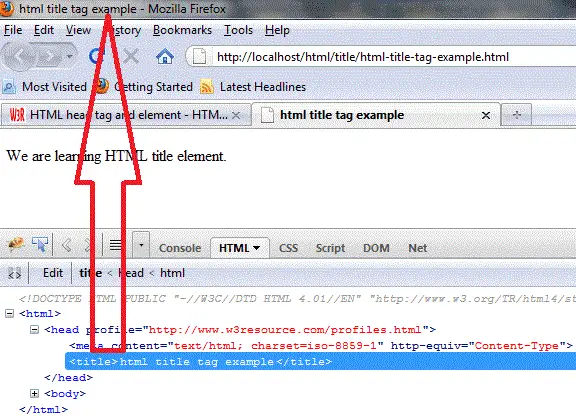
Meta Title
This is an important tag, and some SEO specialists claim it’s the most crucial element. The <title> tag shows up as the clickable title on the search results page, so it’s often the first thing that users will see about your website. It’s also what a user sees when looking at a browser tab, defining the page’s title. It’s a requirement for HTML documents.
There are a few things to keep in mind to write this type of tag correctly. You’ll need to use less than 55 characters because browsers and search engines may cut it off if you have a longer title. Make sure that each page on your website has a unique title, too.
If programmers have any primary meta keywords, they should use them at the beginning of the title tag and put their company’s name at the end. When coders write meta titles, they need to keep the target customers and users in mind.
Meta Description
The meta description tag is similar to the meta title tag because it also appears on a search engine’s results page. Instead of seeing it as a clickable link, your users will see it directly under the title and URL in the results on Google or another search engine.
Although some experts claim that meta descriptions don’t directly impact SEO like other meta tags, professional programmers should still include them; the benefit being that meta description tags provide much of the impact for click-through rates (CTRs), which does affect SEO directly.
Search engines look at the number of clicks a page has, which influences a website’s rankings. That means anything affecting CTRs is important. Keywords used in a meta description also appear in bold text, which helps an engine choose if a page matches a query.

For your pages’ descriptions, keep them between 125 and 155 characters. Make sure that the descriptions accurately reflect the content of the page. Programmers should use the description to quickly market the page to users and make them more likely to click the link and go to their website.
If you want to, you can use a meta description generator to help figure out what the description should be. These websites can help brainstorm ideas, and they can show how your description might look on the search results page of Google or another search engine.
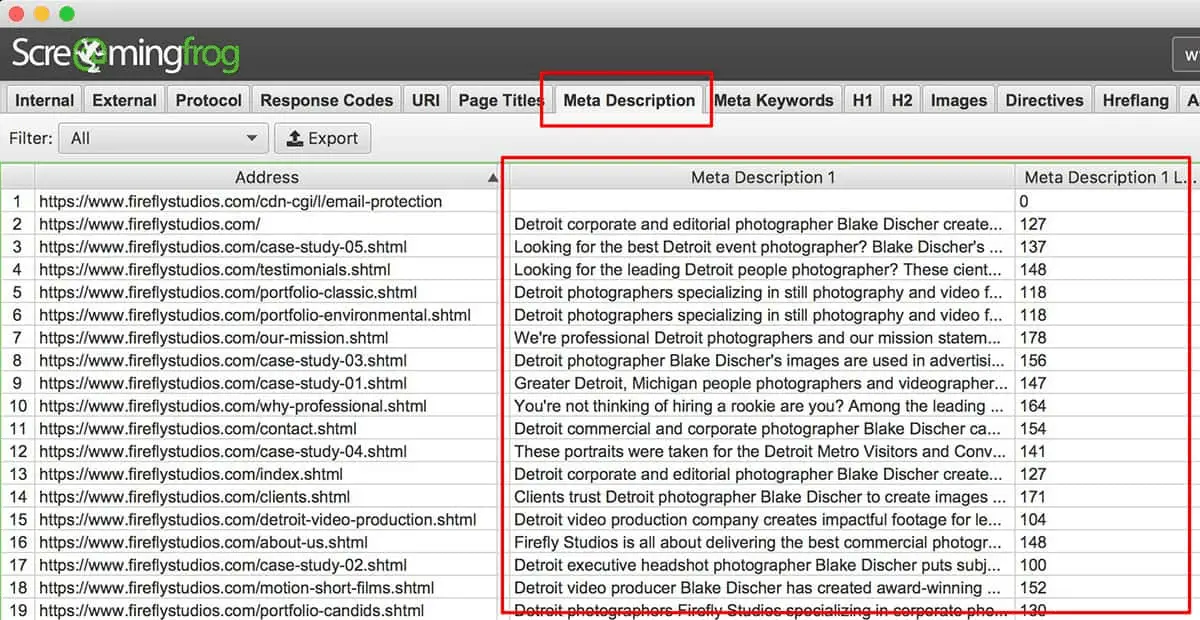
Screaming Frog is a powerful tool for performing advanced technical website audits and on-site optimization. This tool also analyzes the site’s metadata by calculating the pixel width of page titles and meta descriptions.
Meta Viewport
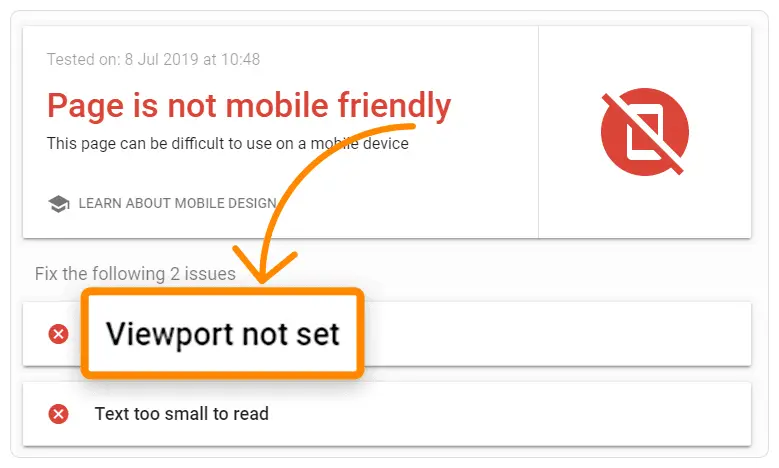
Understanding meta viewports relies on understanding what a viewport is. Viewports relate to the size of a user’s visible page area, which varies depending on the device. Mobile phones have smaller viewports than computers and laptops.
Defining your website’s viewport lets you control the dimensions of the page and its scaling. You’ll need to specify the content width and the scale. By doing so, the coder tells the page to use a device’s screen width to alter the width of the content.
Although it might not seem like it, viewport attributes impact SEO because search engines favor responsive design and mobile-friendly websites. In addition, the viewport attributes direct the browser on how to control the scaling and dimensions of a page.
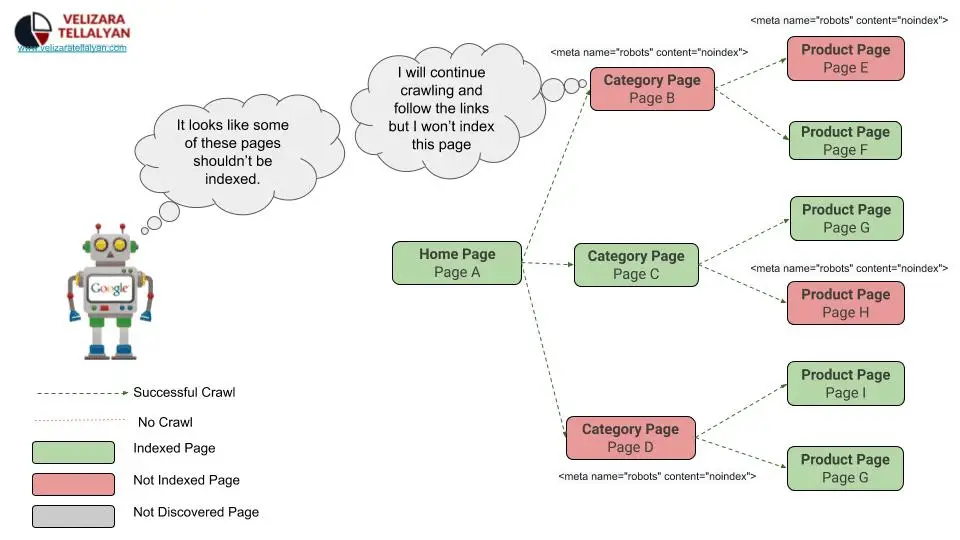
Meta Robots
This tag is another key tag for your SEO strategy, and it tells a search engine whether or not to index or follow a page. Generally, search engines will index and follow pages by default, so programmers don’t need to tell them to do so.
However, indicating to search robots that they want them to index the page on the results page (SERP) and follow it may not be a bad idea. SEO specialists can also manually request Google to recrawl a page using the “Fetch as Google” tool.
If you want to ‘assign’ a specific user-agent, take the standard tag <meta name=”robots” content=”[PARAMETER]”> and replace the “robots” with the name of a crawler such as Googlebot.
Sometimes, SEO specialists want to tell search engines not to index or follow a page. In that case, they’d indicate particular indexation-controlling parameters:
- Index – a search engine indexes a page by default with no meta tag added.
- Noindex – a search engine doesn’t index a page.
- Follow – the crawler follows all the URLs on a page and passes equity to the linked pages.
- Nofollow – the crawler doesn’t follow a specific link or pass along any link equity. Mind that it doesn’t prevent the page from being crawled completely. Therefore, it should be marked ‘noindex nofollow’ to hide it entirely from indexation.
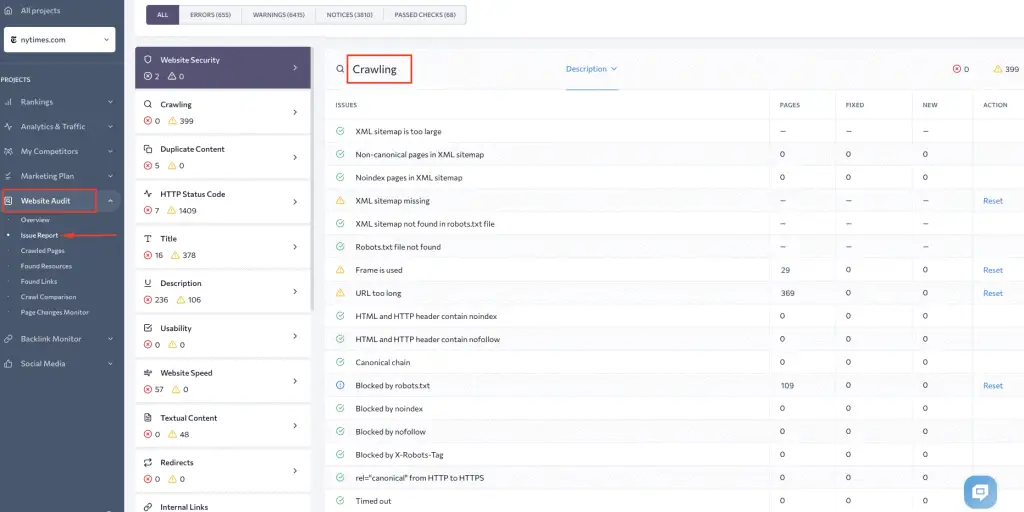
To keep track of your HTML tags, it is required to run a regular site analysis. It will maintain the effectiveness of your site’s promotion and timely spot errors. You can easily conduct a technical website audit with the SE Ranking and get a detailed report of every page with the noindex, hreflang, rel=”canonical” and rel=”alternate” tags, including subdomains and pages specified in the XML sitemap.
Programmers don’t have to use a meta robots tag, but it’s a good idea to use it on pages that they don’t want to show up on a result’s page. Thin pages with little helpful information for users, thank you pages, product launches, and promotion pages can negatively impact your SEO unless you hide them with a robot attribute. You also might want to hide admin pages from results pages as well.
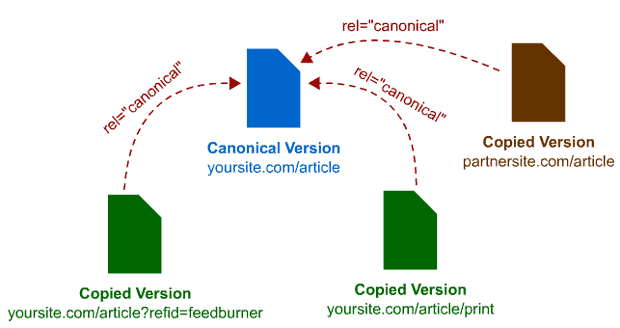
Canonical Meta
This part is where things may get a bit confusing, especially for newer programmers. Google and other search engines don’t like duplicate content, and when they crawl through URLs with similar content, you might see your SEO tank. That’s because search engines won’t know which versions to add to their indices, which link metrics apply, or how to rank different versions for search results.
Sometimes, especially on e-Commerce websites, programmers will find repeat (duplicate) content. That’s because many eCommerce sites will sell the same product with the same information. For example, a manufacturer might send a basic description to websites that sell one of its products. Many websites won’t alter that information, causing the exact details on many different websites.
Canonical meta tags (aka “rel canonical”) combat issues that might be caused by duplicate or similar content on your website. This tag informs search engines which version of a URL should appear in search results, and it eliminates SEO issues caused by multiple URLs having identical or similar information.
Meta Content Type
This part of a meta tag is necessary to declare a character set for your webpage, and you should have it on every page on the website. Excluding it can affect how your page loads in someone’s browser.
For example, you may see something like this: <meta http-equiv=”content-type” content=”text/html; charset=UTF-8″>. In this case, the content attribute defines the character set for the search engine.
Including this tag is crucial for browsers to understand a web page. While the actual character set won’t affect the ranking, omitting the tag altogether might. If the coder doesn’t include this tag, a browser won’t decode the site properly, and it will display the wrong text.
What Are the Core HTML Tags for SEO Content?
While a typical HTML document contains a few sections, the majority of the HTML tags are found in the body, so what are the core tags for SEO content? Let’s take a look at some certain essentials for organizing content, placing links, optimizing images, as well as some tags that comply with best practices.
Headings
Coders primarily use heading tags to tell the topic of a web page and structure its content. The tags range from h1 tags to h6 tags, with h1 being one of the most important tags on a page.
People often confuse headings and titles. Headings emphasize sections of a page, and the title tag defines the title of the page in search engine results. Use the h1 tag as the name of the page for users, and use a title tag as the name of the page for search engines. You can also use h2-h6 tags for different sections or paragraphs.
Heading tags play a role in your SEO when search engine robots look at your pages. These tags tell crawlers what the content on the page is about, with the h1 tag telling the crawler the key topic of your article. The other heading tags help crawlers understand what paragraphs and sections are about. Programmers can always check the crawl stats in Google Webmaster Tools.
These tags also help facilitate content scannability, allowing users to quickly comprehend your content which enhances their user experience. Setting heading tags also improves your website’s accessibility and usability, which is a factor in SEO because Google and other search engines favor accessible websites.
Links and Anchors
If an SEO specialist needs to link to another page, they use <a> tag with an href attribute, indicating where the link goes. The <a> tag is also commonly known as an anchor.
For SEO, make sure that the anchor text is SEO-friendly by making it brief and relevant to the page it links to. Search engines will use the external anchor text to reflect how other websites see yours and what your pages might be about. If enough websites believe that a page on your site is essential for a set of words, then the page will rank well for those terms even if they don’t appear within the page’s content.
Alt Text
Alt attributes are essential parts of the <img> or image tag and are especially useful for visually impaired people. Alt attributes will appear in the image container if the image can’t load. Programmers aren’t required to use them, but they actually should.
Search engine crawlers read the alt text you include because they can’t see the image in the way a human can. To follow the best practices, ensure that your file name and alt text are easy to read and incorporate essential keywords.
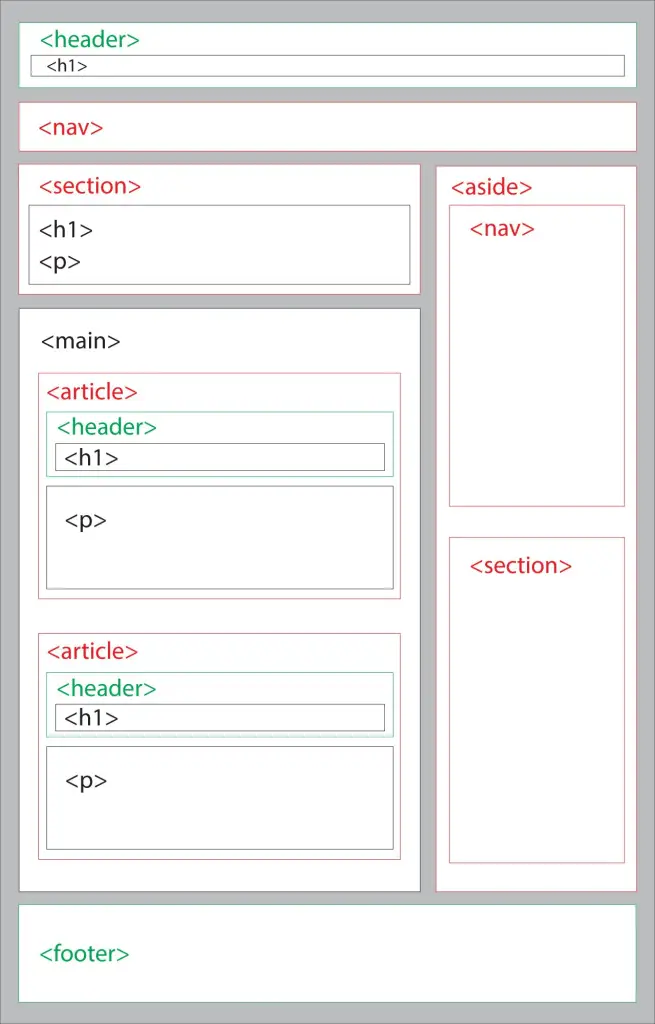
HTML5 Semantic Tags
There are a few other semantic tags that also play an important role in SEO. Let’s briefly look at them one by one.
- <header>. The header tag represents a container that’s for introductory content or navigation links. Although coders can use it in place of the h1 tag, that isn’t the best practice, and it might negatively impact SEO.
- <nav>. The nav tag is for navigation links, and not every single link should be inside this element. It’s only for major navigation. Screen readers, browsers, and search engine crawlers will use this element to figure out if it needs to alter the initial rendering of the content.
- <main>. You should use this tag to tell crawlers what the main content of a website is, and it should be unique to the page. Don’t put any information like sidebars or navigation in this area, and don’t use more than one <main> element on one page.
- <article>. This tag should contain any self-contained content. Articles should make sense by themselves, independently from the rest of your website. They might include blog posts or news stories. On the SEO side of things, search engines like Google can put more weight on the content inside of this tag. It also helps reduce the number of times you use the <div> tag.
- <figure>. A figure element is somewhat similar to an image tag, but it only specifies self-contained content like illustrations, photos, code, or diagrams. To maximize your SEO, use the <figcaption> tag alongside the figure element. That way, you can add more information to the content.
- <footer>. A footer tag typically appears at the bottom of your website, and it can contain information like copyright, contact, or a sitemap. For SEO, the footer tag can tell search engines things like company information.
- <mark>. This tag is relatively simple compared to the other ones. All it does is define the text that needs to be marked or highlighted somehow.
- <aside>. Aside tags are similar to section tags, but these focus only on secondary content related to the surrounding content. They’re usually used for sidebars in documents, and they don’t do anything special without CSS. A new article, post, or a call to action might be a good reason to use an aside tag.
The diagram below shows an example of how these elements coexist on a web page.
{kind=link}
Bad Practices
Programmers can use some tags, like the <span> and <style> tags inside of other tags, like <h1> or <a>, but it isn’t always best practice to do so.
For example, style tags allow you to edit your page’s CSS without switching to an internal or external stylesheet. However, inline CSS isn’t the best practice, and you should avoid using it in most cases, especially if you have multiple developers working on one project or have multiple pages with the same inline styles.
Span tags act as inline containers instead of inline styles, and the coder can assign a class to them to alter with CSS when one uses them inside another tag. In most cases, the span tag isn’t considered the best practice because the coder can use a blockquote, cite, or <em> tag in its place.
Small Choices Can Make a Difference
When it comes to Google and SEO, there are many aspects to keep in mind. Many different meta tags can impact a website’s rank, and best practices are difficult to follow sometimes. Making sure that the programmer uses the proper tags in the right places is an excellent place to begin.
So remember, when building your page, consider the preferences of search engine robots as well as the human eye. Be sure to place follow and no-follow tags appropriately to maximize your crawling budget, as well as using proper <h> tags to increase readability.
This may seem like a lot to take in, but with enough practice, you’ll be able to rank higher in the search results by writing professionally optimized SEO code.

Related Articles

How to Start a PROFITABLE Programming Blog From A-Z (2022)
Are you looking to: … get your name out there as a programmer? … share your solutions with the world?…

Developer Side Hustle: Convert Learnings Into Earnings
Developers are always learning, but they may not know how to turn that knowledge into more significant earnings. For example,…

Top 10 Simple Programmer Posts of 2021
A comprehensive look at the top posts on Simple Programmer in 2021, from a most read to a most engaged…