 Microsoft SQL Server 2016 has recently taken the lead in relational database management systems (RDBMSs). The combination of high performance, security, analytics, and cloud compatibility make it the leading RDBMS. SQL Server 2017 even supports the programming languages R and Python, which further increases its appeal among data scientists and data professionals in academic institutions.
Microsoft SQL Server 2016 has recently taken the lead in relational database management systems (RDBMSs). The combination of high performance, security, analytics, and cloud compatibility make it the leading RDBMS. SQL Server 2017 even supports the programming languages R and Python, which further increases its appeal among data scientists and data professionals in academic institutions.
It’s an exciting time to be a SQL Server developer for many reasons that are outside the scope of this article, but to concisely summarize them: SQL Server has not only become the number one RDBMS—it has also become more than an RDBMS.
With these impressive new editions of SQL Server in mind, you may find yourself wondering how to extract the most value from the features that you anticipate to be the most impactful to your overall productivity, particularly if you lack experience. If, on the other hand, you are not attending every webinar and skimming every article over new features, then don’t worry too much; plenty of companies are still using SQL Server 2008 R2, particularly those in heavily regulated industries like finance and healthcare.
I would caution anyone against focusing on any of SQL Server’s new features and functionality without first becoming proficient in (if not mastering) the essential skills.
This article explains why metadata is valuable, what metadata is, and then walks through two practical problems that are solved with Transact-SQL (T-SQL) code that references metadata. From querying catalog views to using metadata dynamically, you should walk away with knowledge that will make your SQL Server development skills significantly more valuable by reducing the amount of time and effort it takes to familiarize yourself with data and solve problems independently.
Regardless of your industry, company, or even current version of SQL Server that you are using, these three common skills that you can learn are highly transferable—even across relatively large jumps in software versions (e.g., from SQL Server 2008 R2 to 2014).
Three Essential SQL Server Skills for Developers
SQL is the first and most obvious skill that you need to be competent in. One of the primary reasons for learning this scripting language (besides the fact that it’s fun) is how transferable it is—even across other RDBMSs. Of course, I am talking about American National Standards Institute (ANSI) Standard SQL (SQL) syntax, not necessarily T-SQL, which is Microsoft’s dialect of SQL. Personally, I have also found that it is easier to learn new elements of SQL/T-SQL syntax than to adjust to new features on a graphical user interface. For the purposes of this article, I’ll focus on T-SQL based on the assumption that anyone reading this piece is some variation of a SQL Server developer.
PowerShell is the second skill. PowerShell is another scripting language that allows users to automate a variety of useful tasks, which often involve running SQL Server Reporting Services reports, scheduling jobs, and basically doing a lot of database administrator (DBA) work. What makes PowerShell even more attractive, however, is the fact that it is a replacement for the Windows DOS batch language (i.e., the batch language that you use in command prompt) that uses .NET objects and methods. Yet another reason for its value is the fact that, unlike T-SQL, PowerShell can automate tasks that span the Windows and SQL Server environments.
Besides these two rich scripting languages, there’s a third skill that would greatly benefit any SQL Server user who is well-versed in it, which is the use of metadata. Technically, understanding SQL Server metadata (for the purposes of this article, all references of “metadata” will imply “SQL Server” unless explicitly specified) is a subject to study and an opportunity to exercise and apply skills (i.e., memorizing relationships and learning T-SQL)—not really a skill in itself. For this reason, whenever I refer to “the use of metadata,” I mean, “how well a developer applies knowledge of metadata in T-SQL.”
I would argue, however, that metadata is also one of the most overlooked and underestimated topics within the developer community (while learning T-SQL is clearly not). Many introductory SQL Server or T-SQL books do not even discuss it until later chapters, if at all, and even then, in little detail.
Familiarizing yourself with SQL Server metadata is a considerably more valuable skill than most instructors seem to think, particularly for beginners, because it is a practical means of applying knowledge in theoretical concepts within the SQL language, database design, and both physical and logical processing.
Even for more experienced developers and DBAs, SQL Server metadata can be extremely valuable, because its utility scales with your creativity and competence in other areas of database design and programming. Throughout the article, I will provide examples of T-SQL scripts that increase in complexity and demonstrate how familiarizing yourself with metadata can prove invaluable when trying to solve problems.
Before I dive into the examples, however, I should make a couple of important general points. Microsoft’s website, commonly referred to as the “Books Online” (BOL), is the single greatest resource that I can recommend on this topic. In fact, you should view this page to familiarize yourself with the various types of metadata and this page on how you should access the metadata (i.e., use catalog views).
Basic Metadata Queries
The simplicity and flexibility of querying object catalog views enables even users with minimal SQL knowledge to explore objects and relationships in a database remarkably well. Allow me to demonstrate why metadata is useful to developers with a quick example.
For those interested in following along, please note that I am using SQL Server 2016 Express Edition and the AdventureWorks2014 sample database (both are completely free).
Pretend that you are a new employee of the fictional company, Adventure Works Cycles. After looking at a few tables, you notice that a column called “BusinessEntityId” appears quite a bit. Wouldn’t it be nice to have a query display every column with that name in the database? Understanding the basics about SQL Server metadata makes that easy.
Since you are aware of [sys].[all_objects], [sys].[schemas], and [sys].[all_columns], you can write a simple query to achieve that single view of BusinessEntityId.
Here is the result set:
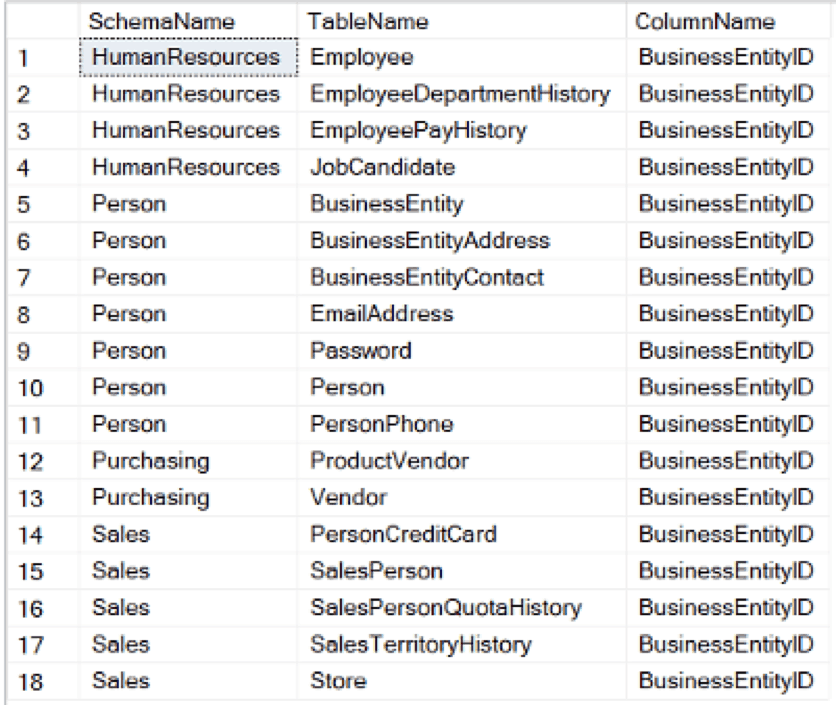
Metadata is for more than just writing basic ad hoc queries. Consider the opportunities to make incredibly complex queries to answer extremely difficult or time-consuming questions. For example, how many duplicate indexes exist in a given database? What types of indexes are they?
Familiarity with metadata, especially via catalog views and dynamic management views (DMVs), is extraordinarily valuable regardless of your current T-SQL skill level. It is a fun and accessible mechanism for honing your knowledge of both the T-SQL language and the company’s master data that scales with your rising competency in database programming.
Now follow the comments in the remaining queries that demonstrate how exploring the master data with metadata (combined with a bit of business knowledge) can help you independently answer questions.
There’s a lot that you can learn independently about a company’s data if you know your way around SQL Server metadata.
Advanced Application of Metadata
But what about the more advanced application of metadata? What if you are an experienced developer who has worked at a company for years? Why should you learn about SQL Server metadata? Well, a more complicated example may convince you.
In one of Grant Fritchey’s presentations at a PASS local user group event, he described 10 tips on how to improve SQL Server performance. One of them was to look for nested views and rewrite them (by joining to tables, ideally). By “nested,” I mean the views are created referencing other views in their definition. The more levels of nesting within a given view definition, the greater the performance will decline.
The obvious solution is to not write nested views, but even that is no excuse for avoiding their hypothetical existence, because by doing so, you are handicapping your performance tuning proficiency and relying on the assumption that it will not become a problem in the future. Moreover, if you are investigating database performance problems and are unsure about whether or not nested views plague your database, then it may be worth your time to at least take a look to verify whether or not this issue is one that you must untangle or not.
But how could you go about doing this? Besides manually right-clicking every view in the object explorer and reviewing the definitions, why not create a metadata stored procedure that utilizes dynamic SQL to give you the answer?
I wrote two stored procedures, which are referenced later in the article, that help get you started on solving this problem. There happens to be a system function called “sys.dm_sql_referenced_entities,” which accepts two input parameters: a qualified view name (i.e., “schema.view” or “[schema].[view]”) and a “referencing class.”
For the purposes of this article, just know that we are interested only in database objects, which means that we need to use the string “object” in the second parameter. In case you were wondering, you can view triggers’ references if you use a different referencing class. For more information, see this link.
Now that I’ve mentioned “dynamic sql,” I should address two categories of possible concern: security and performance.
Dynamic SQL Costs: Security and Performance

Dynamic SQL is basically “SQL that writes SQL.” While it is incredibly useful in stored procedures, it comes with some costs. Before elaborating on these costs, however, I must state that they are negligible compared to the long-term effects that nested views could have on a database.
I am well aware that SQL-injection is a serious security risk that becomes possible when developers write dynamic SQL. Fortunately for me, the “parent” stored procedure does not accept user input and is not intended for use in any customer-facing applications. More specifically, the dynamic SQL does not accept user input from the front end of an application to obtain values for its parameters.
If, on the other hand, your concern is the performance of dynamic SQL, then I have two responses for you:
First and foremost, the purpose of this “nested views” exercise is to increase the overall performance of a database by solving a potentially serious problem, and one that should occur only very infrequently (that is, unless you have a team of developers who continue to nest views on a regular basis, in which case, you have a much bigger problem).
Since the problem (in theory) occurs infrequently, then you should desire to run the code only infrequently, which means the poor performance of the code will only be of concern the few times you run it. In other words, you’re completely missing the context of the problem if you are focused on the performance of these procedures at the expense of the performance of the entire database, so don’t think too critically about the performance of this code (but feel free to tune it more if you can).
Secondly, you may also be concerned that performance suffers because of the very non-relational nature of dynamic SQL. I strongly agree with the notion that anyone writing SQL should strive to do so relationally (i.e., by writing in a manner compliant with the principles of set theory), whenever possible. Unfortunately, there is no alternative approach to solving this problem that complies with the relational model any more than this one. If you disagree, or have found any way to improve my code by making it more relational, then please contact me immediately. I should also mention that I have written an entire article on this subject.
To quickly summarize the criticisms: Security risks and performance concerns are negligible compared to the long-term and cumulative, performance-degrading effects that nested views may have on a growing database. The code itself may not be optimized for scalability and performance, but it will, if used properly, help you ensure that your databases are.
Making Your Metadata Dynamic
So, is dynamic SQL worth these risks? The best answer I can give you is that it depends on the value of the problem that you are trying to solve. Dynamic SQL is an additional tool in the SQL developer’s tool belt that dramatically increases the number of ways to solve problems. The first step in automating this nested view scavenger hunt is to write a dynamic SQL statement using sys.dm_sql_referenced_entities (I’ll use “referenced entities” for the sake of brevity) to return the names of all referenced views and the frequency of references:
[dbo].[CountObjectReferences]
[dbo].[FindNestedViews_v3]
Between dynamic SQL and cursors, there are some features of T-SQL that are simply unavoidable parts of this solution. As far as I’m aware, the only way to make this idea work is by using dynamic SQL to execute the referenced entities system function.
Additionally, the only way to run dynamic SQL multiple times is by using a cursor (unless you want to try something with extended stored procedures, but that is outside the scope of this article). Besides dynamic SQL and cursors, you are left with a few important design decisions.
Once you have a stored procedure that executes the dynamic SQL statement that passes in the database, schema, and view names, you might want to slow down and think about the design—specifically, by answering the design question: “Do I want to break this into another stored procedure and call it, or encapsulate all logic inside one giant stored procedure?”
The fact that I’ve contained the dynamic SQL inside a separate stored procedure, rather than include it as the first part of one huge stored procedure, was a deliberate design decision on my part. At the time, I thought it would be easier to read and maintain. Moreover, I wanted to ensure that the execution plan for the dynamic SQL was consistent (one of the advantages of stored procedures is preventing the optimizer from occasionally generating different execution plans). I also found that it was easier to write and test.
Deciding how to store the qualified views, pass them to the [dbo].[CountObjectReferences] stored procedure, store the results of the cursor, and then display the final output is one of the more difficult parts of this problem. We can use table variables, temporary tables, user-defined tables, or views.
How ironic would it be if you used a nested view in this stored procedure? Technically, it would be ironic only if the database you wrote the stored procedure in did not have any nested views except the one in the procedure. Now that is irony!
I opted for temporary tables because I am not as familiar with table variables; I don’t want to maintain a user-defined table as part of this process, and there’s no security concern preventing me from accessing the data directly (thus ruling out views). The ability to add indexes later and easily change the scope of the temporary tables between local and global are also appealing characteristics that affected my initial decision.
I did not clarify from the start whether I wanted a more detailed result set—which provides the user with as much relevant metadata as possible—or include the bare minimum amount of data in exchange for increased performance, maintainability, and simplicity.
The latter turned out to be my preference after reflecting on the original problem and thinking that I want to be able to run these stored procedures on an ad hoc basis and I only need a simple result set in order to find the nested views. Basically, you want to return the smallest amount of information possible to answer your question. In our case, that means returning all of the view names that contain other views and, ideally, how many levels of nested views exist between the original view and the table.
Before moving on, I must point out that I knew using a cursor would limit how scalable this approach would be. On the other hand, nesting views in a database isn’t exactly a scalable approach to database design either, so please keep that in mind too.
Key Points for Further Consideration
These stored procedures would not have been possible if I had not known about [sys].[views] or the referenced entities function. In fact, I originally joined [sys].[all_objects] on [sys].[schemas] and [sys].[all_columns], which performed worse than the version referenced in this article. It is also important to point out the security concerns behind metadata privileges and dynamic SQL.
Since security policies vary depending on the size of an organization and by its industry, whenever taking a job that involves SQL Server development, use these factors to keep your expectations within the same ballpark as the DBA(s) you will be working with. For more information on SQL Server metadata security, check out this article by Kalen Delaney. In fact, I would also suggest reading more from Delaney on the subject of SQL Server metadata.
Secondly, metadata access requires approval from your DBA. While there is a small security risk in allowing any users access to system metadata, it’s really a matter of how much your DBA or company trusts developers. Unless you work in a highly regulated industry, it’s unlikely that this will be a problem for you.
Exploring Other Uses for Metadata

When using the term metadata, I have been specifically focused on system metadata. I should also point out the usefulness of DMVs, since they are heavily used and relied upon among DBAs, and suggest that any developer should be familiar with all of the above information.
What I’ve found most challenging is finding the correct DMV or system metadata quickly—a problem that would certainly diminish as I take my own advice from the previous paragraph. On that note, I encourage anyone who experiences the same problem to use my first example and modify it based on what you are looking for (i.e., modify it to look for DMVs or system views of interest based on keyword searches).
With additional practice, metadata and DMVs will become incredibly valuable to you by maximizing your ability to solve problems in SQL Server without any assistance from third-party software. Even better still, much of your code that relies on SQL Server metadata will still function in Microsoft Azure, making the application of metadata an even more transferable skill.
Considering the chaos of rising and falling technologies, transferable skills are becoming increasingly harder to identify and rely on, which makes developers’ lives (at times) unnecessarily difficult. Thus, the value of SQL Server’s metadata is a testament to Microsoft’s dedication to user empowerment, which is as sure an indication as any that they are creating products with you, the developer, in mind.

Related Articles

12 REALITIES of Daily Life as a Programmer
What’s the daily life of a programmer like? A programmer’s daily life consists of auditing and debugging code, coding new…

13 POWERFUL Productivity Tips for Developers
Great productivity is one of the best soft skills you can have as a developer. I’ve used these tips to…

Impostor Syndrome as a Programmer
Believing that you’re somewhat unqualified for your job is a problem faced by the best of us. When those thoughts…